
分散式GPU SQL引擎BlazingSQL最新版本應用程式與Apache Spark測試比較,在執行相同工作負載且維持相同成本的條件下,BlazingSQL的執行效能是Apache Spark的20倍。
在去年10月才對外發布的BlazingSQL,是採用RAPIDS資料科學框架的GPU加速SQL引擎,RAPIDS為一個全GPU端到端資料科學工作管線的開源函式庫集,BlazingSQL擴展了RAPIDS,並讓使用者以Apache Arrow在GPU記憶體中執行SQL查詢。
在一月的時候,BlazingSQL先進行了一次效能實驗,他們在Google雲端平臺上建立了Apache Spark以及BlazingSQL兩個叢集,為維持相同成本配置,Apache Spark叢集使用8個8 CPU的節點,在BlazingSQL叢集使用一個搭載Tesla V1000 GPU與10個CPU的節點,官方提到,這兩種硬體配置每月的支出約都在1500美元左右。
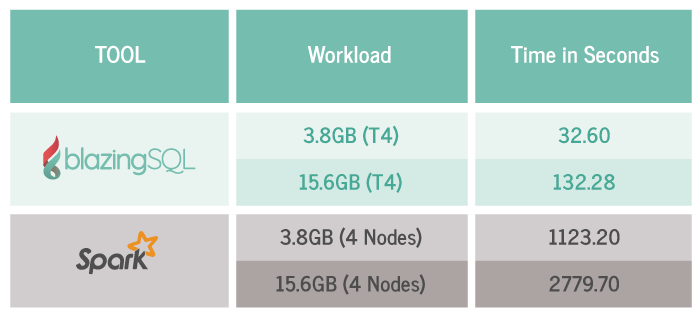
官方在GitHub公開了測試程式碼,他們讓這兩個叢集執行相同的端到端分析工作負載,對資料進行特徵萃取工程,並以機器學習函式庫XGBoost進行訓練。對兩種大小的資料集進行測試,BlazingSQL的執行速度比Apache Spark快了5倍。
而現在他們又再次對新版BlazingSQL做了一次基準測試,執行與上次相同的工作負載並在成本相當的條件下,BlazingSQL的執行速度是Apache Spark的20倍。在新測試中,除了BlazingSQL叢集用了Nvidia的T4 GPU,還改善了BlazingSQL中的SIMD Expression Interpreter。
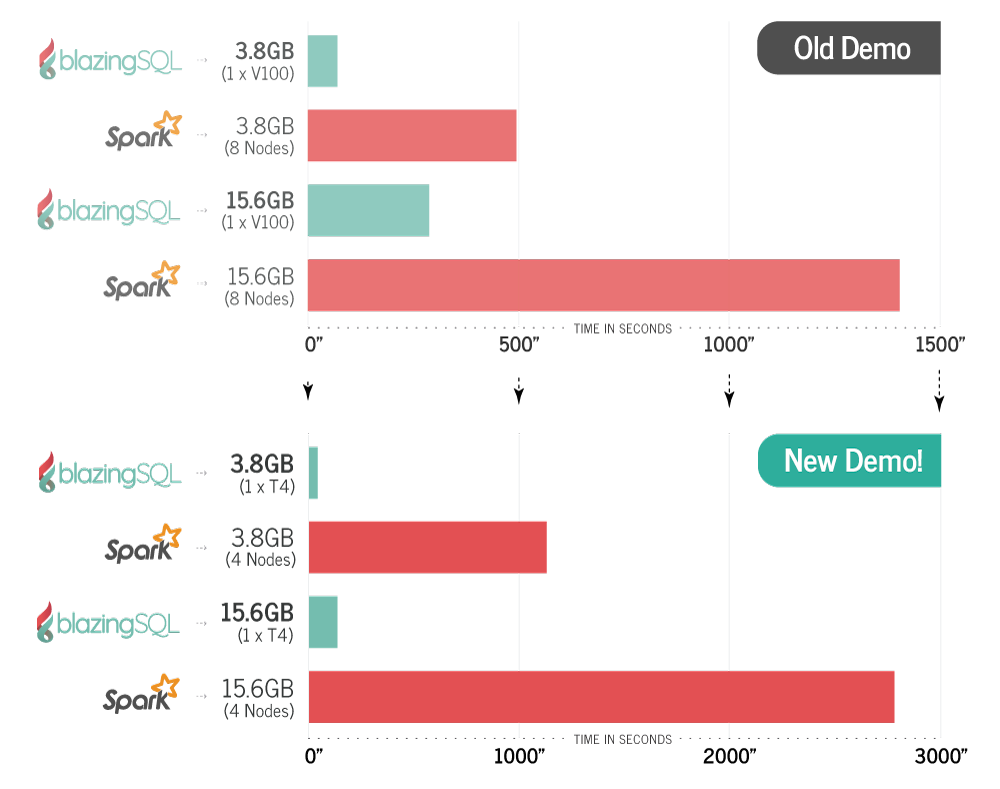
官方表示,雖然T4是一顆入門級的GPU,價格較便宜但是卻擁有良好的效能,比起前一個實驗他們所使用的V100,價格便宜許多,因此將成本列入比較的限制時,這次Apache Spark叢集使用的節點也降低至4 CPU,以維持相同的成本支出。

不過,官方表示,這次試驗大部分的效能增加,是來自於引擎的改進。BlazingSQL正在發展一個專為GPU DataFrames(GDF)打造的GPU執行核心SIMD表達式直譯器(SIMD Expression Interpreter)。SIMD表達式直譯器可以讓系統同時接收多重輸入,包括GDF欄位、文字,並在未來將能支援函式。
當系統載入這些輸入時,SIMD表達式直譯器能夠最佳化GPU上暫存器的配置,因此能進一步最佳化GPU執行緒的占用率以及效能,讓虛擬機器能同時處理多重輸入以及輸出,官方舉例,過去BlazingSQL處理SELECT colA + colB * 10, sin(colA) — cos(colD) FROM tableA,會將該查詢轉換成+、*、 sin、cos和—等5個單獨的運算,最後產生兩個輸出,SIMD表達式直譯器則使用colA、colB和colD三個輸入,並在單個核心執行全部5種運算,而後產生兩個輸出。官方表示。以這樣的方式系統只需要載入一次colA、colB和colD,而非原本的兩次。
目前SIMD Expression Interpreter的進度只能支援過濾器和投影運算,但已經能加速大多數的熱門SQL運算。由於BlazingSQL仍處在發展初期,目前仍在0.2版本,官方也坦承說,BlazingSQL目前只能以單節點和單GPU執行,因此他們在實驗上限制了運算資料量。
熱門新聞

2026-03-06


2026-03-11




2026-03-06

2026-03-09