Uber
Uber AI實驗室開源釋出訓練和測試深度學習模型的AI工具箱Ludwig,該工具箱建立於深度學習框架TensorFlow上,標榜不需要寫程式就能完成模型的訓練和測試工作,提供一系列的AI模型開發工具,像是透過視覺化的方式,呈現評估模型、比較模型效能和預測結果,目前於GitHub平臺以Apache License 2.0授權釋出。
Uber表示,目前市面上有許多深度學習相關的函式庫,像是TensorFlow、PyTorch、CNTK、MXNET,以及Chainer,Uber決定避免重複開發性質類似的工具,因而在這些開源函式庫的根基上,打造AI開發工具箱Ludwig。Uber曾開源釋出在PyTorch上建立的深度機率程式語言Pyro,以及允許在多個GPU和電腦分散訓練深度學習模型的框架Horovod。
近幾年來,深度學習模型已被證實能夠高效執行多種不同機器學習任務,包含電腦視覺、語音辨識、自然語言處理等,而在Uber內部,深度模型也被用在多種任務中,像是客戶服務、物體辨識、優化地圖、串流聊天溝通服務、預測和防範詐騙等,為了簡化深度學習模型的測試和訓練工作,AI工具箱Ludwig已經在Uber內部開發超過2年,主要用於Uber的多項專案,像是從駕駛人駕照萃取資料、從對話擷取客戶興趣、預測餐點送達時間等。
Uber指出,Ludwig特別的地方是能夠讓非AI專家更容易理解深度學習模型,對於經驗豐富的AI開發和研究人員而言,也能透過Ludwig縮短模型的開發周期,簡化開發原型過程和處理串流資料的工作。
Uber將Ludwig設計為一種通用型的工具箱,主要用於處理新的機器學習問題時,能夠簡化模型開發和比較模型架構過程,設計的核心原則包含免寫程式、具有通用、靈活性和擴展性,並能夠透過視覺化的方式,讓開發者更能理解模型。在通用性的部分,Ludwig允許開發者使用CSV的表格文件和資料序列格式YAML配置文件,來訓練深度學習模型,YAML配置文件能夠加快模型原型設計的速度,將編碼的時間從數小時縮短至數分鐘,若有超過一個輸出目標變數,Ludwig會執行多任務學習,也就是同時預測所有的輸出。
而針對靈活和擴展性的部分,在模型定義中通常會包含額外的資訊,特別是對每個特徵屬性預先處理資訊的時候,每個特徵屬性都需要個別的編碼器、解碼器和訓練參數,而編碼和解碼器也都需要個別的架構參數,在預先處理和訓練的部分,Uber透過經驗和現有的學術文獻,為多種模型架構參數建立預設值,讓新手也能訓練複雜的模型,同時,能夠個別設定模型配置文件的功能,提供AI專家在訓練模型時有更多彈性。此外,每個在Ludwig訓練的模型都能夠保存,若開發者要用新資料執行模型得到預測結果時,就能重新載入模型。
其中,Ludwig一項主要的新概念是為特定的資料類型提供獨立的編碼和解碼器,也就是說,每種資料類型都有特定的預先處理函式,像是文字、圖像和類別(category),如此一來,Ludwig就能夠提供高效率的模組化和可擴展架構,藉由不同資料種類元件的組合,開發者可以用Ludwig訓練多種類的任務,舉例來說,文字編碼器和類別解碼器的組合,就能得到文字分類器,而連結圖像編碼器和文字解碼器就能得到生成圖像標題模型。(圖片來源:Uber)
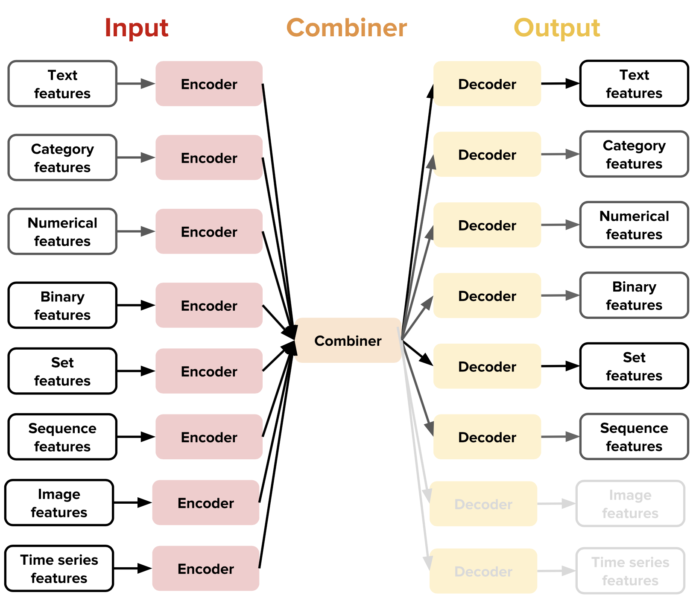
除此之外,每個資料種類可以有超過一個的編碼器和解碼器,例如,文字類型的資料可以用卷積神經網路、遞歸神經網路或是其他編碼器來編碼,接著,開發者可以選定要用哪個編碼器並設置超參數,過程中不需要寫任何一行程式,目前Ludwig提供開發者訓練模型,包含文字分類、物體分類、圖像標題生成、時間預測、序列標註、回歸、語言模型、機器翻譯、問題回答等,對於沒有經驗的開發新手而言,該工具為他們提供開發用於多種應用案例模型的機會,而有經驗的開發者,也能藉由該工具箱研究更多新領域。
AI工具箱Ludwig目前的編碼器和解碼器支援二進制值、浮點數、類別、離散序列、集合、文字、圖像和時間序列等資料種類,還有提供一些預先訓練的模型,像是詞向量模型,未來,Uber還預計支援更多資料種類。
熱門新聞

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23
2026-02-20