
臉書釋出全新自動語音辨識的卷積方法,以及開源目前最先進的端到端語音辨識系統wav2letter++。這個自動語音辨識方法使用卷積神經網路(CNN)進行聲音建模和語言建模,再加上臉書一同釋出的工具,讓其他開發者也能實作出相同的成果。
通常CNN架構比起循環架構(Recurrent Architecture),對於有建模長期相依性的任務更具有競爭力,能夠良好執行語言建模、機器翻譯和語音合成等工作,而在端到端的語音辨識當中,循環架構在聲音建模和語言建模上卻更為普遍。
而臉書的這項研究,是在端到端語音辨識中使用CNN架構,臉書表示,端到端語音辨識可以輕鬆的擴展到多種語言,另外,直接從原始語音學習,則是解決音訊品質變化大的好方法。臉書的語音團隊現在釋出第一個全卷積的語音辨識系統,從波型到最後的單詞轉錄為文字,系統的可學習部分,能僅由卷積層組成,而這樣的效能則可以與循環架構相當。
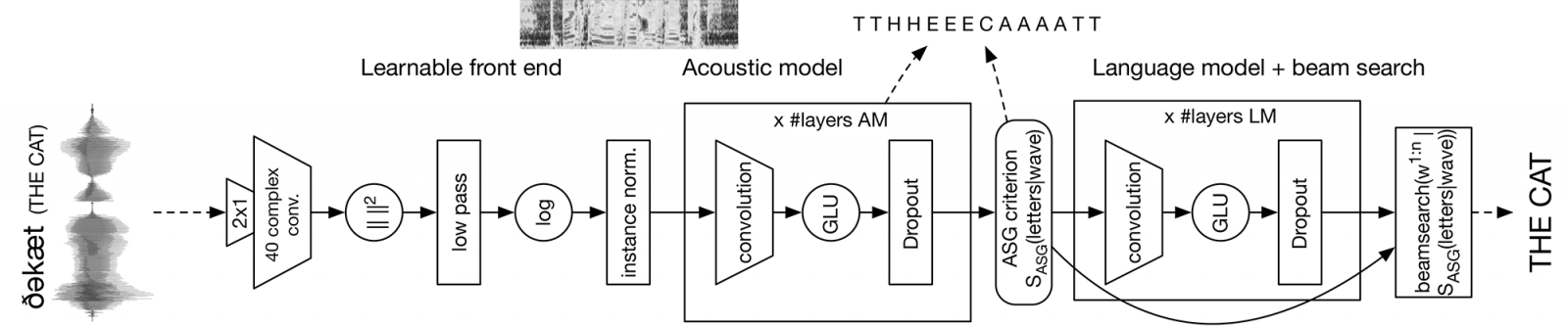
另外,臉書還發表了快速且靈活的獨立機器學習函式庫Flashlight,這是由臉書的語音團隊以及Torch和DeepSpeech的開發者共同設計的,能為現代C++進行JIT編譯,並針對CPU和GPU後端,實現效能與規模最大化,而Wav2letter++工具則建立於Flashlight之上。
由於高效能框架Wav2letter++能進行快速迭代,因此可以加速研究進展,並方便的對新資料集和任務進行模型最佳化。臉書釋出全新自動語音辨識的卷積方法的同時,也同時釋出了Flashlight和Wav2letter++開發框架,以實現成果的可重複性。
熱門新聞

2026-03-06

2026-03-06

2026-03-09

2026-03-06

2026-03-06


2026-03-09
Advertisement