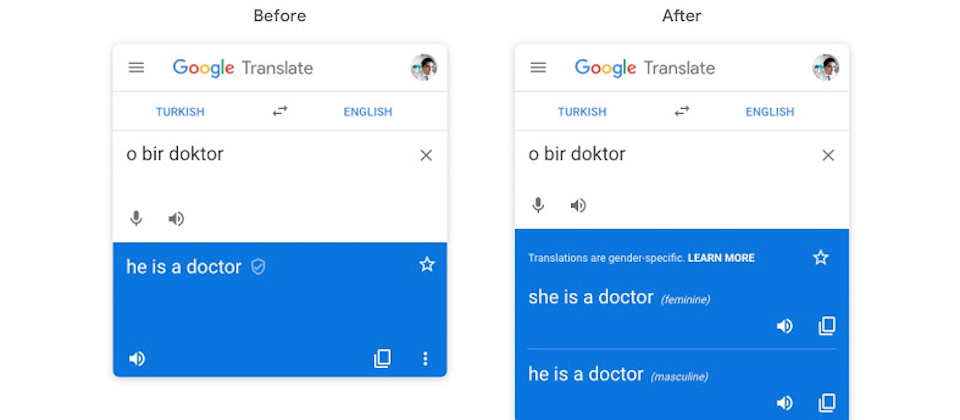
Google日前發布透過提供兩種性別翻譯結果的方式,來解決原本Google翻譯中存在的性別偏見問題,最近則是公開了性別翻譯背後的技術,針對句子中涉及性別的文字進行翻譯其實並不容易,為此Google必須重新更改目前的翻譯框架,目前支援從英語翻譯至法語、義大利語、葡萄牙語和西班牙語,以及將句子從土耳其語翻成英語。
為了能夠在句子中辨識出涉及性別翻譯的文字,Google開發了3個步驟的方法,來解決英語提供性別的翻譯問題,首先系統會先偵測輸入的語句是否適用於特定性別翻譯,接著,透過強化過的神經機器翻譯(Neural Machine Translation,NMT)模型,產生針對男性、女性和中性的3種翻譯結果,最後,再將這3種翻譯結果與預設的翻譯結果進行比較,來決定送出最佳的翻譯結果。
以土耳其語為例,許多與人相關的文字,性別都是中立的,並沒有分性別,要偵測出特定性別進行翻譯就相當困難,這樣的複雜性代表無法透過機器學習系統,在性別文字的清單中,找到像土耳其語這樣性別中性的詞彙,根據Google統計,在土耳其語翻譯的請求中,大約有10%的翻譯性別是模糊的,不管是翻成男性或是女性都可以。
首先,要偵測這些翻譯請求的內容,Google用最新的文本分類演算法,來建立一套可以偵測土耳其語的中性性別系統,由於這是在進入翻譯系統之前,額外導入的步驟,必須要仔細平衡模型的複雜性和延遲性,Google用數千個經過人類標註的土耳其語範例來訓練模型,土耳其語的專家針對這些範例進行分類,標示出該範例是否為中性性別,最後,透過卷積神經網路的分類系統正確分辨,需要進行特定性別翻譯的語句。
找出該語句後,Google用強化過的的神經機器翻譯NMT系統,產生男性化或是女性化的翻譯結果,當沒有性別請求時,訓練過的模型會產生預設的翻譯,若確認使用者的查詢是性別中立的,Google會在翻譯請求中加入性別前綴(prefix)。
最後,評估翻譯準確率的步驟,則是用來決定要呈現什麼樣的性別翻譯給使用者,由於不同性別的訓練資料不同,兩種性別的翻譯結果也可能不同,評估系統會比較所有的翻譯結果,找出最適合的翻譯結果呈現給使用者。未來Google將會擴大特定性別翻譯的功能到更多語言,也會處理解決非二元性別在翻譯中的偏見問題。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-03

2026-03-02

2026-03-02