Nvidia
Nvidia的研究團隊最近開發了透過深度學習技術教導機器人完成任務的模型,機器人能夠藉由觀察人類的行為動作,學習如何與人類一同完成任務,Nvidia開發這套模型即是為了要增進人機合作,讓機器人未來可以與人類合作無間。
要求機器人完成真實世界設定的任務,需要與機器人溝通任務的預期結果和過程中如何完成的提示,透過人類的示範,能夠更有效地提供機器人完成任務最佳方式的提示。
Nvidia的研究團隊用Titan x GPU訓練了一套神經網路模型,來執行觀察行動、生成計畫、執行計畫的任務,結果顯示,機器人只需要觀察一次人類在真實世界的示範,就能學習到如何完成任務。
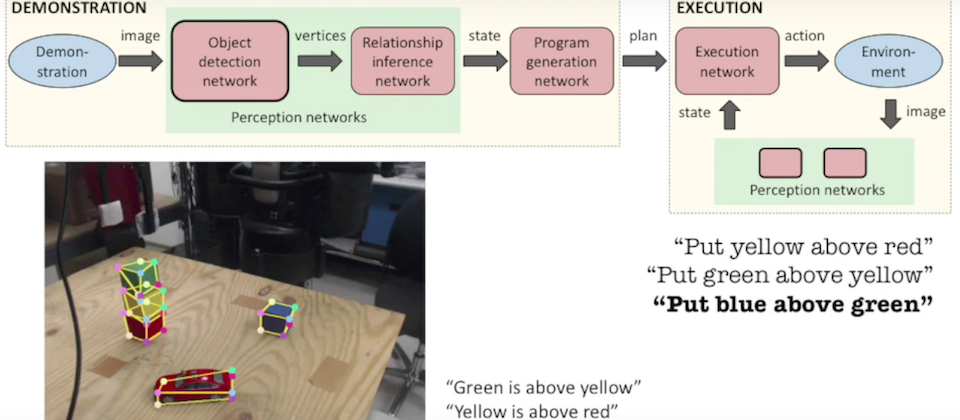
研究人員建立了3個神經網路,首先,機器人的攝影機會接收即時的影片,透過物體偵測網路,利用卷積式網路辨識拍攝中的物體,接著將這些物體資訊,輸入到另一個神經網路,也就是物體關聯性的網路,該網路會偵測物體神經網路分析影片中的物體和位置關係,再由計畫生成網路,來產生如何重製觀察影片動作的計畫,最後,執行動作的神經網路會執行制定好的計畫。
只要機器人觀察人類完成任務的過程,就能自動產生可閱讀的重製步驟計畫,在機器人執行動作之前,使用者可以快速確認並修改任何問題。
Nvidia表示,這項讓機器人學習人類動作的技術關鍵在於,利用合成的資料來訓練神經網路,現在傳統訓練神經網路的方法,都需要大量的已標示(Labeled)資料,對訓練網路來說,是一大瓶頸,透過合成資料生成的方式,能夠輕鬆地產生大量的標記訓練資料。
此外,該模型還有一個特別的地方,Nvidia指出,該模型第一次將以圖像為中心的使用域隨機化(Domain randomization)方法,用在機器人的研究上,使用域隨機化是一種用來產生多種不同合成資料的技術,欺騙感知網路將現實世界的資料,當成其他不同種類的訓練資料,研究人員為了確保神經網路不會依賴攝影機或是環境,選擇了用以圖像為中心的方式,來處理資料。
熱門新聞

2026-03-06



2026-03-06

2026-03-09


2026-03-09

2026-03-09