Google前陣子釋出AI相機Clips,最近則在AI研究部落格公開用Google Clips自動捕捉重要瞬間和短片的實驗方法,找來攝影專家手動為訓練資料集的影片片段評分,讓AI模型學習如何辨識出有趣的拍攝場景。
Google研究團隊過去一直在研究如何用深度學習方法,讓電腦視覺演算法辨識拍攝照片的元素,像是人、微笑、寵物、日落、知名的景點等,Google Clips的設計圍繞著3個重要的原則。
首先,所有的計算都必須在行動裝置上完成,這樣一來,除了可以延長相機電池的壽命之外,還能夠減少延遲性,在行動裝置上執行計算也意味著,所有的拍攝片段都只會存在裝置上,並不會外流,同時可以保護用戶隱私,用戶能夠自行選擇是否要儲存和分享。
第二個原則是團隊希望相機可以拍攝短片,而不是只有單張的照片,因為動作更能夠保留當時的回憶,且拍攝短片比起照片,更容易捕捉到重要的時刻。
最後一個原則是要聚焦於捕捉人和寵物的鏡頭,而不是一些抽象場景的藝術照片,也就是說,Google的研究團隊不會嘗試著教導Clips如何調整構圖、色彩平衡、光線等,而是讓Clips自動聚焦於包含人和寵物有趣互動的場景。
而Google研究團隊是如何訓練Clips捕捉重要的拍攝時刻和場景?如同許多機器學習的訓練過程,要先從訓練資料集開始,首先Google研究團隊建立了包含數千個影片的資料集,且該資料有多種不同的場景、性別、年齡和種族,接著,研究團隊找來專業的攝影師和影片的剪輯專家,手動挑選出短片中最好的片段,這些挑選過的片段能夠讓演算法模擬。
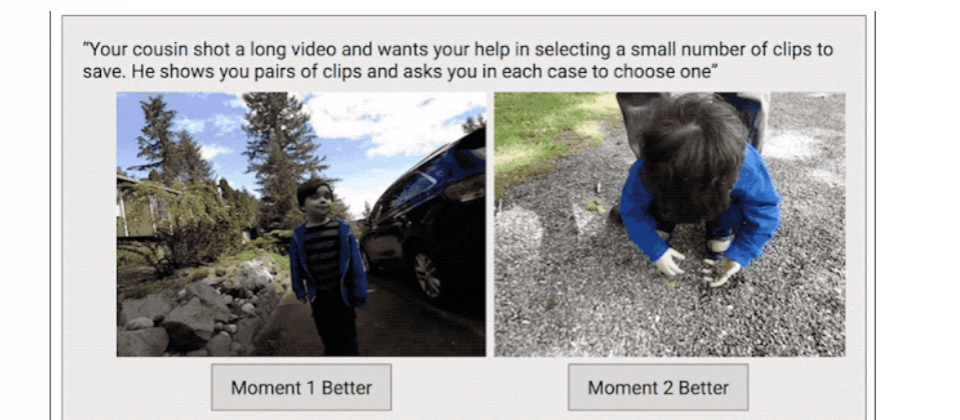
不過,要訓練演算法學習主觀的判斷是非常有挑戰性的,需要有合適的量化指標讓演算法了解內容的品質,像是從完美到最糟的。為了解決這個問題,研究團隊收集了第二個資料集,為了要為整段影片創造出連續的品質分數,團隊將影片分成多個片段,隨機挑選兩個片段,讓攝影專家選出較好的片段。
研究團隊不讓專家直接對影片評分,而是透過成對的對比方法,因為二選一的方式,比直接給予一個品質評分,更為直觀、簡單,專家用成對對比方式的挑選結果也較為一致,能夠讓研究團隊計算影片品質分數,Google從超過1,000支影片中,收集了超過5千萬對的片段,來讓人類專家評分。
完成資料集後,就進入訓練模型的階段,要訓練神經網路模型評估相機拍攝每張照片的品質,首先先假設系統了解場景內的主角,像是人、狗、樹等,如果假設正確,就能利用辨識照片內容來預測品質分數。
為了能夠辨識訓練資料集中照片的物體,研究團隊利用Google相片和圖片搜尋服務背後的機器學習技術,該技術可辨識超過27,000種不同的物體、概念和動作的標籤,由專家挑選出大約數百種需要的標籤,來設計辨識模型。
為了讓辨識模型可以在裝置上預測任何照片的品質,Google研究團隊訓練了電腦視覺模型 MobileNet相片內容模型(Image Content Model),來模仿以伺服器預測的模型,該壓縮的模型可以從照片中辨識出最多有趣的元素,將不相關的內容排除。
最後一個步驟即是從輸入照片的內容,預測品質分數,除了用訓練資料集來確保預測的準確度之外,研究團隊還為已知的有趣場景調整品質分數的權重,像是重複出現的臉部、微笑和寵物、擁抱、親吻和跳舞等。
有了預測有趣場景的模型後,相機就能根據預測結果,即時決定要捕捉哪些畫面,大多數的機器學習模式都是用來辨認照片中的物體,但是,Google Clips要辨認的目標更為模糊且主觀,因此需要結合客觀和意義的內容,來讓專家建立主觀的AI預測模型,此外,Clips的運作模式並非全自動,而是需要與人類一同合作,為了拍攝到更好的結果,需要由人確保相機鏡頭聚焦於有趣的場景。
熱門新聞


2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23