在2004年,Google有位參與基礎架構建置的資深工程師Jeffrey Dean公開發表了Google雲端運算核心技術模式MapReduce和Google運用這項技術的成果之後,不到幾年,雲端運算如野火燎原般,深深地影響了現在資訊技術和服務的發展。
現在的網路服務,往往是提供全球性的服務規模,使用者往往數千萬人甚至上億人,應用程式需要承載的服務量非常龐大,也就衍生了各種雲端運算技術來因應這樣龐大規模的運算量需求。這類網路服務的特徵是,每一次使用者執行的運算量不大,可能只是幾隻網頁程式,但是同時有很多人使用,可能相同的程式要執行數億次,例如Facebook的讚按鈕,每天有數億人點擊,其實只是靠幾隻程式在運作。
為了解決這樣的大規模低運算需求的任務,現今的雲端運算發展出兩大類技術,第一是以Amazon EC2經驗和VMware平臺所主導的虛擬化技術,另一類就是類似MapReduce 這類具有高擴充性的分散式運算技術。
虛擬化技術是從基礎架構的角度來解決大規模應用的需求,透過可以不斷增加的虛擬機器,來提供執行環境,可以解決各類應用上的需求。而像MapReduce這類分散式技術則是從應用程式的角度,將原來龐大的運算任務數量拆解成小量且可以分散處理的程式段落,再分派給大量實體伺服器來計算。
MapReduce的基本概念其實不難懂,用一個真實的數錢幣故事來解釋。有位企業主為了刁難銀行,用50元硬幣和10元硬幣償還316萬元的貸款,數萬枚硬幣重達1公噸,還得找來吊車才能送到銀行,幾位行員七手八腳花了好幾個小時才清點完畢。銀行只要不斷加派人手,就能縮短清點時間,例如能立即找到100個人手,10分鐘內就能完成,不會影響到正常銀行運作。
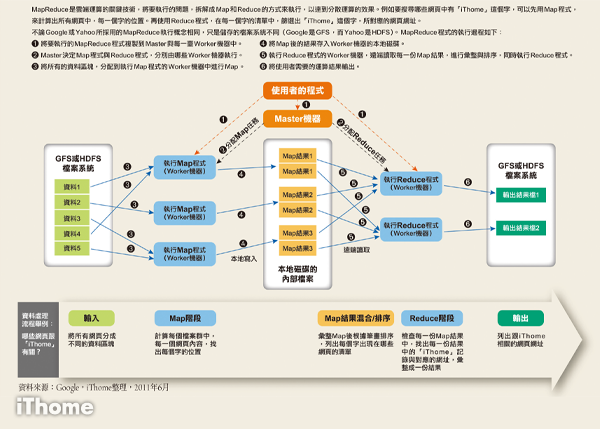
就像這個不斷加派人手來清點錢幣的做法一樣,MapReduce可以不斷增加更多伺服器來提高運算能力,增加可承載的運算量。透過Map程式將資料切割成不相關的區塊,分配給大量電腦處理,再透過Reduce程式將結果彙整,輸出開發者需要的結果。
Google也設計了一個叢集式架構來進行MapReduce運算,在MapReduce系統中包括了Master主機和Worker主機,開發人員將要解決的問題拆解成Map程式和Reduce程式,透過Key-Value方式傳值。Master主機會將這些程式指派給大量的Worker主機來執行,有些負責執行Map,再將執行後的結果交給執行Reduce程式的Worker主機,再彙總出問題需要的答案。
整套系統只要不斷增加新的伺服器,就可以擴充新的Worker主機,由Master主機分配任務,即使系統不關機也可以擴充硬體設備。
Hadoop源自Google MapReduce技術
Google發表MapReduce後不久,開源社群在2004年也用Java實作出一套使用MapReduce技術的開發框架Hadoop,讓Java開發者可以很容易寫出雲端運算的應用,Google和Yahoo都有不少工程師參與這項計畫。
Hadoop內建了一個分散式檔案系統HDFS,也同樣透過Master節點和Slave節點的從集架構來提供分散運算,核心設計概念都是來自Google的MapReduce模式和分散式檔案架構,等於是Google雲端運算的開源版本,Hadoop也是目前最受歡迎的開源雲端運算框架。許多企業也都開始利用Hadoop來進行大規模的資料分析,例如eBay、中華電信、華碩投資的全球聯訊等。
Hadoop能支援異質的執行環境,每一臺伺服器的硬體可以不同規格。開發者只要將Hadoop程式和設定檔複製到每一臺伺服器下,並且將分析資料放入Hadoop的NameNote虛擬檔案系統中,NameNode會自動切割使用者傳入的檔案,再分散到不同Slave伺服器中的HDFS檔案目錄中。
最後,在Master伺服器中啟動Job Tracker工具來執行Hadoop程式,Job Tracker會自動啟動其他Slave伺服器上的程式,依據設定檔進行分散運算。Hadoop提供了一套網頁介面的管理系統,可讓開發者追蹤每一臺伺服器的執行情形。
用MapReduce解決運算擴充需求,而NoSQL解決資料擴充需求
雲端運算的出現,解決了超大量運算的問題,但後來,資料量越來越多以後,又出現了傳統資料庫無法負荷的問題。尤其是近幾年竄紅的社交型網站,資料成長速度更快,你可以想像假設一個社交網站隨時上線的使用者有1萬人,若這些人每天和10位朋友打招呼,一天就會產生10萬筆資料。若是像Facebook,每天有5百萬名臺灣用戶上線,光是臺灣地區產生的資料量,每天至少有5千萬筆。即使採取了分散式運算技術,將程式執行分擔到大量伺服器上,但是執行後產生的資料,仍然需要一套高擴充性的資料庫系統來儲存。
為了解決資料庫擴充維護的問題,最近幾年也發展出另一種非關聯式的資料庫,通稱為NoSQL資料庫,目前主要可分成4種,包括Key-Value資料庫,記憶體資料庫(In-memory Database)、圖學資料庫(Graph Database)以及文件資料庫(Document Database)。
Key-Value資料庫是NoSQL資料庫中最大宗的類型,這類資料最大的特色就是採用Key-Value資料架構,最簡單的Key-Value資料庫中,每一筆記錄只有2個欄位,也就是Key欄位和Value欄位,每一個Key對應到一個Value欄位,沒有傳統關聯式資料庫的欄位架構(Schema),讀取資料的方式也只有設定值、取出值或刪除值等簡單的操作,沒有像SQL語言那樣可以進行Join的複雜查詢。但是Key-Value架構的好處正是因為沒有Schema,只要建立另一群Key值,就等於是建立了另一個資料表,而因為每一群資料之間沒有關連,可以任意切割或擴充。
其他,記憶體資料庫是將資料儲存在記憶體的NoSQL資料庫,文件資料庫則是用來儲存非結構性的文件,而圖學資料庫不是專門用來處理圖片的資料庫,而是指運用圖學架構來儲存節點間關係資料架構,例如用樹狀結構來組織從屬關係或網狀結構來儲存朋友關係。
不論是NoSQL資料庫技術、Hadoop分散式運算開發框架,或MapReduce分散開發架構,這些技術最終目的是具備不斷擴充的能力,這類雲端運算技術的出現,提供了一種全球性的,可支援大規模網路應用服務的運算能力,而且具有水平式擴充的特徵,可以不斷擴充資源來供給更大的運算資源,不同於傳統的垂直式擴充,只能整套硬體升級到新版,才能獲得更大效能。
雲端運算關鍵技術MapReduce的執行示意圖
4大類NoSQL資料庫

熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
{kind=link}
")
2026-02-09
")
2026-02-09

2026-02-09