
作者/數位發展部多元創新司 吳品樺分析師
進入網路時代後,隨著資料大量的累積,探勘潛藏其中的資訊已成為人類創新的原動力。政府將資料釋出作為開放資料 (open data) 已是常見的做法,也加速了公共政策、產品服務等可衍生廣大效益的領域發展。然而,當資料涉及個資或敏感內容時,從符合法律規範、保障隱私及考量承擔風險的角度來看,就不宜逕行開放這些資料。
為了解決上述資料再利用的痛點,數位發展部(後簡稱「數位部」)推動「隱私強化技術(Privacy Enhancing Technologies,簡稱 PETs)」,以平衡隱私保護與資料運用需求。本文將討論,有哪些隱私強化技術可以幫助我們產生與原始資料特徵相似,但不洩漏隱私資訊的資料集,進而替代原始資料的釋出及運用,讓參與的各利害關係人,都能安心無負擔的進行資料分析。

隱私強化技術效益(來源:數位發展部「隱私強化技術應用指引」)(圖片來源/數位部)
資料分享適用的隱私強化技術
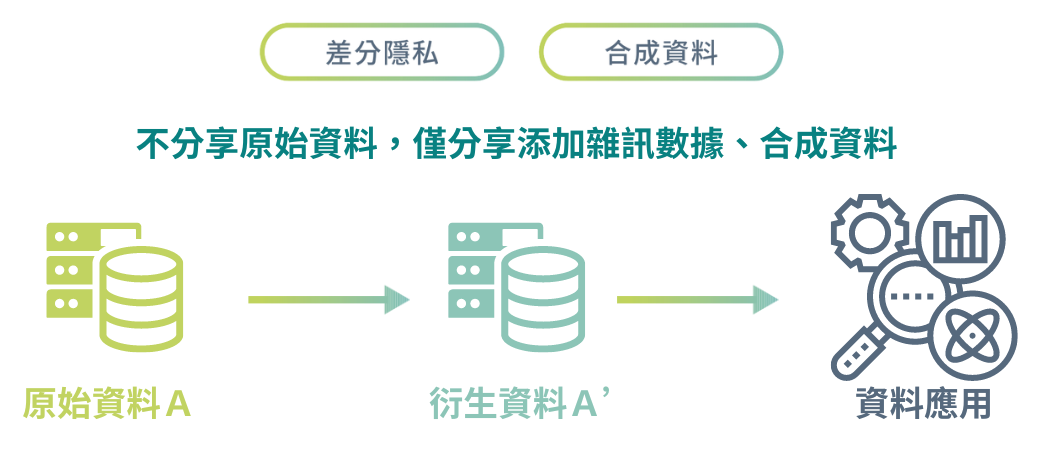
資料分享適用的隱私強化技術(來源:數位發展部「隱私強化技術應用指引」)(圖片來源/數位部)
當我們已經匯集了資料,卻礙於隱私無法直接分享給他人應用時,可以透過如差分隱私、合成資料等方式,取代傳統的k-匿名化等技術,來模糊化原始資料包含的隱私資訊或個人識別資訊,以產生兼顧隱私保護及資料應用需求的衍生資料,供後續資料共享及分析應用。
接下來我們將會簡單介紹各項隱私強化技術:
差分隱私(Differential Privacy, DP)
差分隱私的概念,是在要分享的資料中加入適當的雜訊,把可供識別的敏感資訊模糊化,進而達成保護隱私的目的。產製差分隱私資料集的方式有很多種,其一為統計原始表格式資料態樣及分佈頻率後,在各樣態資料分佈頻率上添加雜訊,以及藉由後處理機制增進雜訊分佈的合理性,最後再轉換回表格的形式,獲得衍生資料集。
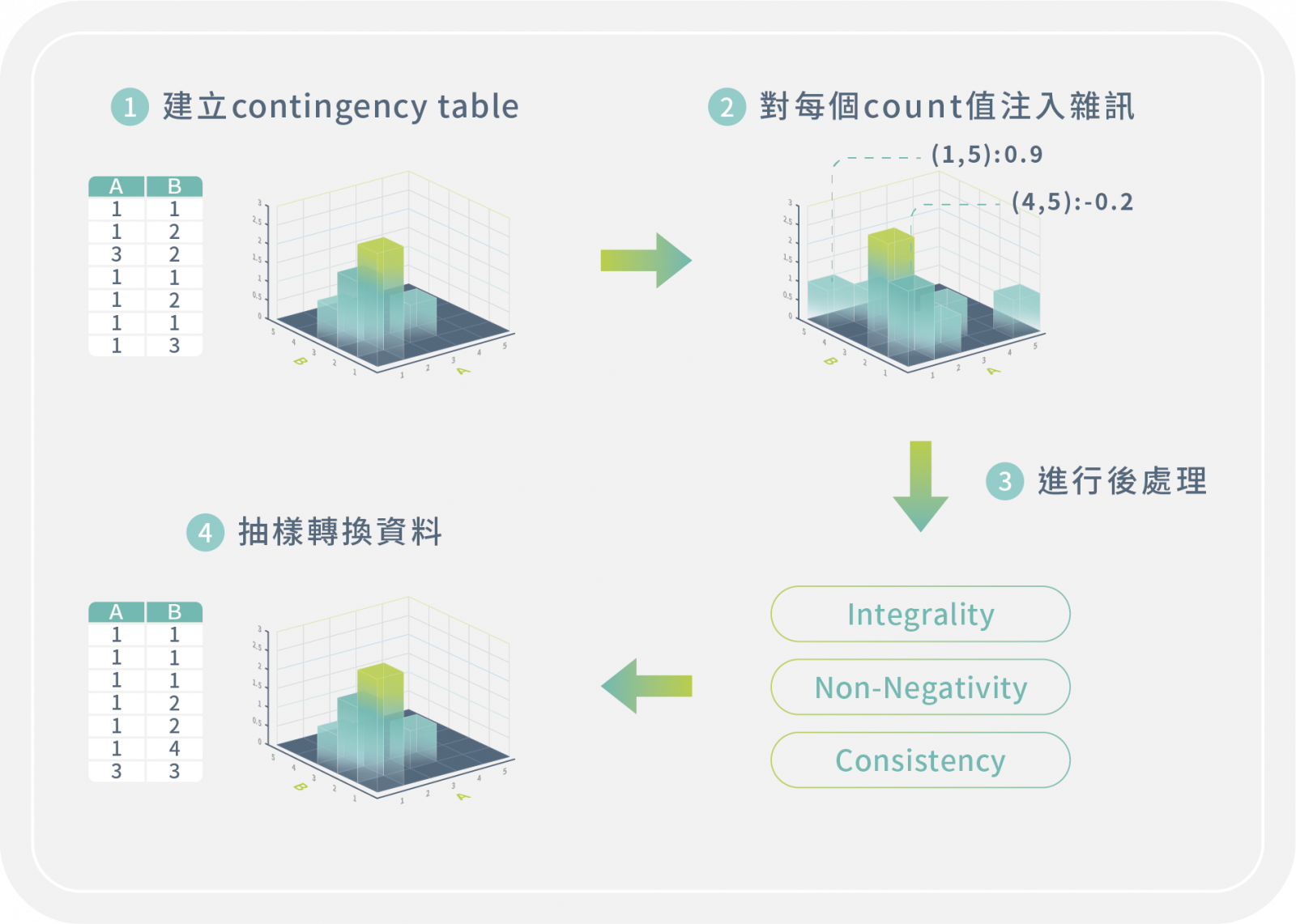
以列聯表機制產生差分隱私資料集(來源:數位發展部「隱私強化技術應用指引」)(圖片來源/數位部)
在處理差分隱私的過程中,加入的雜訊量,會根據設定的隱私預算 (privacy budget, ε) 而變化。其值越大添加的雜訊越少,資料也越接近真實;相對的,當隱私預算越小,隱私保護力越高但資料較失真。該怎麼設定隱私預算並沒有一定的標準,必須在保護力與資料實用性上取得平衡。
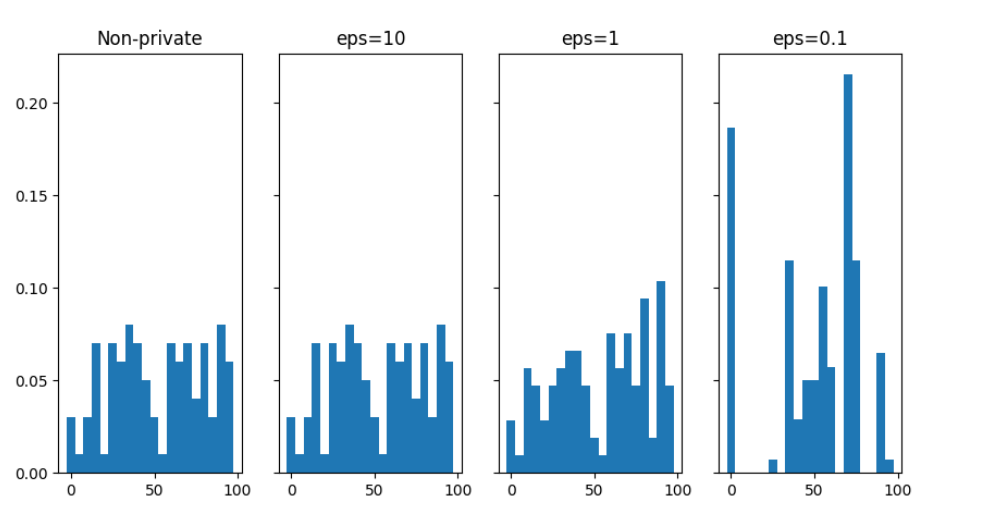
隱私預算對資料的影響(來源:參考國家資通安全研究院「隱私強化技術應用推動計畫」)(圖片來源/數位部)
差分隱私的教母級人物 Cynthia Dwork 在《差分隱私的算法基礎(The Algorithmic Foundations of Differential Privacy )》一書中,將差分隱私比喻為資料持有者對資料當事人的承諾:「當資料當事人允許他的資料被用於任何研究或分析時,無論是否可取得其他研究、資料集或資訊來源,資料當事人都不會遭受到任何不利的影響。」正因為差分隱私可以提供上述的保證,因此特別適合應用在對外釋出資料的情境。
因為資料一經釋出,我們通常就難以約束取得資料的人如何使用資料,也就無法掌控資料,但如果釋出經過差分隱私的資料,即便他人任意操作、應用,都仍能保有符合隱私預算的保護力。例如,美國普查局 2008 年在發佈通勤模式微觀資料時就應用了差分隱私技術,確保研究各地居民的通勤狀況時,不會洩漏居民的居住地或工作地等個資。
合成資料(Synthetic Data)
合成資料是藉由資料生成技術,產生具有和真實資料統計特徵與結構的人造資料。隨著生成式AI的發展,大語言模型(Large Language Model,LLM)和生成對抗網路(Generative Adversarial Network, GAN)都是現在合成資料會使用到的技術。 生成對抗網路架構的特色在於擁有生成器 (Generator) 與鑑別器 (Discriminator):生成器負責生成資料集,鑑別器則負責辨別生成的資料集與真實資料的相似性。反覆經歷生成、鑑別、彼此競爭學習的過程,直到鑑別器無法分辨生成資料集的真偽,則代表該生成資料集已具有真實資料相似的資料特徵,但細部數值完全是生成而來的。
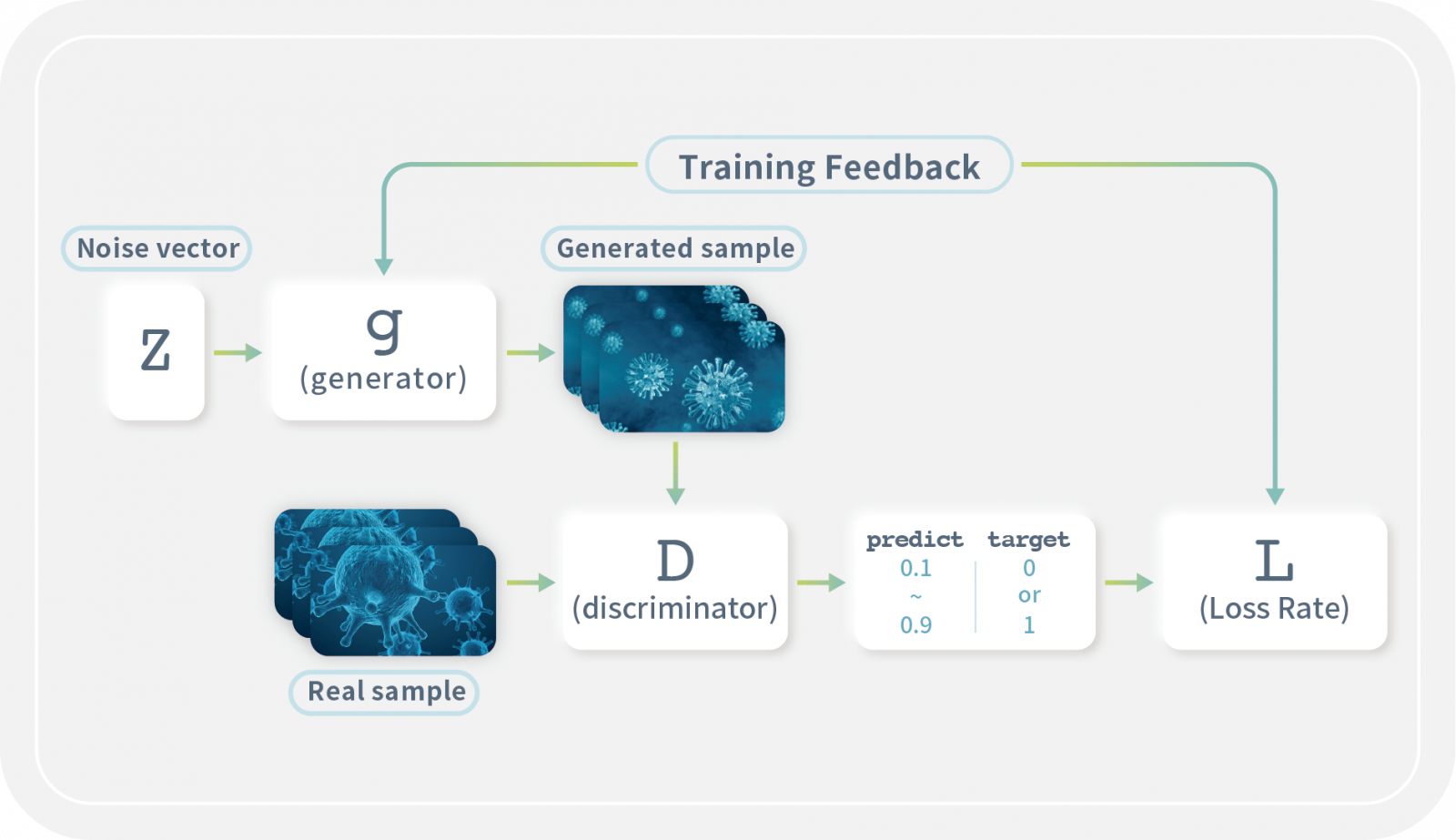
以生成對抗網路產生合成資料(來源:數位發展部「隱私強化技術應用指引」)(圖片來源/數位部)
而大語言模型則是利用其對於文字的理解及預測來產製符合人類觀點的資料樣態,因此生成的資料可能不符合實際應用目的。下圖簡單示範對生成式 AI 提出合成資料的需求,包含資料集的欄位、統計特性、資料筆數等,由生成式 AI 生成一批合成資料。

以生成 AI 生成合成資料示意圖(圖片來源/數位部)
因為合成資料內容是 AI 生成的特性,確保了與真實資料沒有絕對的關聯性。因此,當我們希望盡可能避免揭露真實資料時,可用合成資料替代真實資料進行統計分析、機器學習訓練等應用。以下舉一些相關的使用案例:
●加拿大統計局透過合成資料,生成包含人口普查、健康和死亡資料等敏感資訊的資料集,可在不侵犯個人隱私的情況下,產製高可用性且貼近真實的資料讓黑客松競賽參賽者進行分析。
●英國臨床研究資料庫(Clinical Practice Research Datalink, CPRD),透過合成資料技術,提供接近真實資料的心血管疾病與 COVID-19 資料集,讓研究人員能夠透過各種分析或機器學習手段,進行對社會有益的研究。
傳統的 k-匿名化(k-anonymization)
傳統的去識別化方式,包含抑制/編修(Suppression/Redaction)、遮罩(Masking)、記號化(Tokenization)、雜湊化(Hashing)、泛化(Generalization)等等,像是將表格式資料中的姓名用「〇」取代、將身分證字號置換為另一組符合身分證字號編碼原則的假數字、將年齡 25 歲,泛化為年齡 20~29 歲等,都是去識別化。
其中,k-匿名化結合了各種去識別化技術,運用上述這些方式,來模糊化資料,確保每筆資料都至少有其他 k-1 筆相同的資料來互相掩護。如下圖所示,以年齡為例,若 k=5 則表示每一筆資料都至少要有 5-1=4 筆其他相同資料。
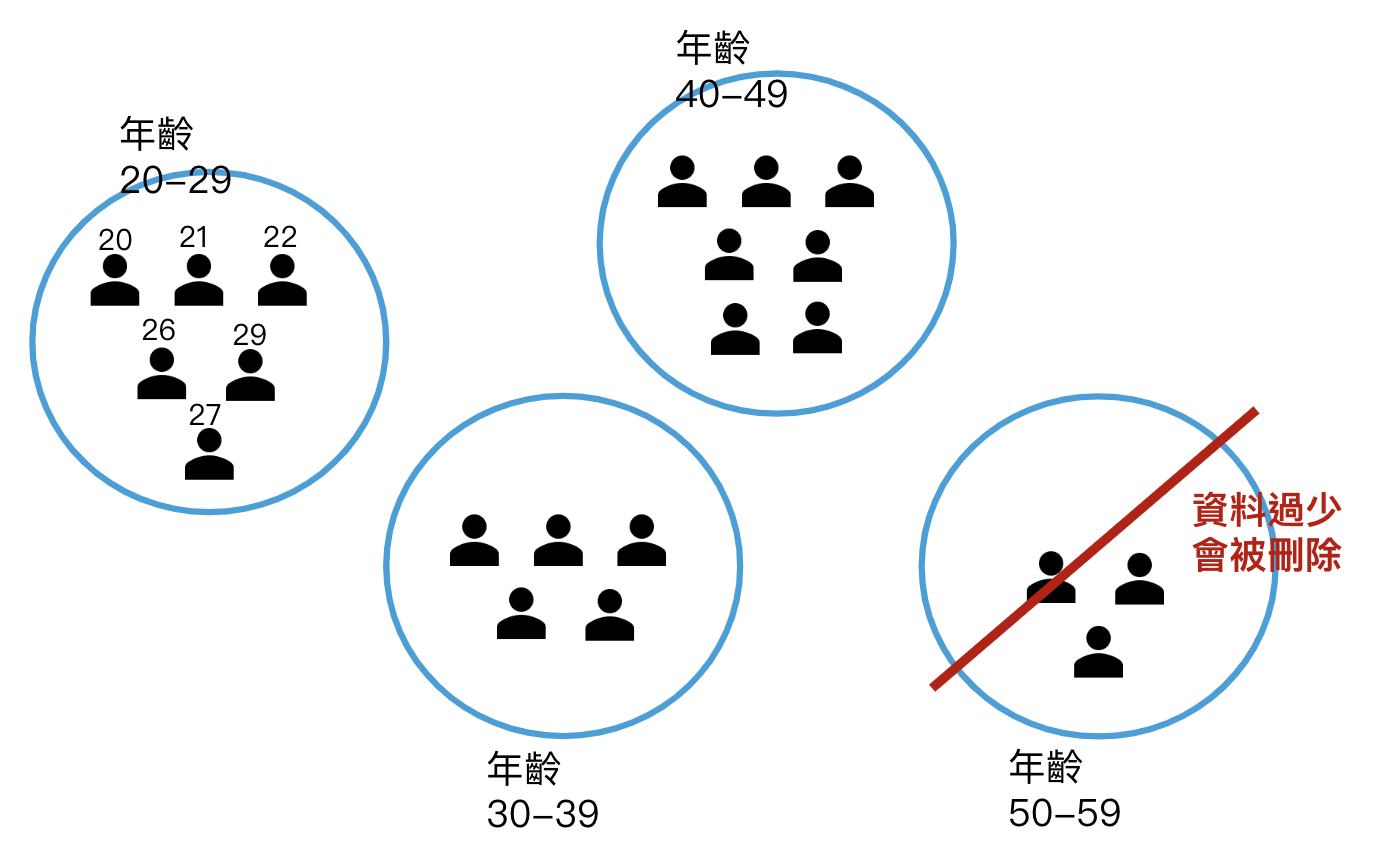
k-匿名化概念(圖片來源/數位部)
k-匿名化是種單純且傳統的去識別化方式,從隱私保護的角度來判斷資料模糊化的程度,要做到較好的隱私防護,k必須設定成較大的數值,資料也會更模糊,但也有可能導致太特殊的資料被刪除;除此之外,真實資料經過k-匿名化處理後對外公開,仍具有一定的隱私洩漏風險。
假設有一份「X區罹患罕見疾病名冊」,經k-匿名化後雖然資料已經模糊化,但是與另一份「X區年齡分佈名冊」進行比對,則有可能被識別出哪些人罹患了罕見疾病。
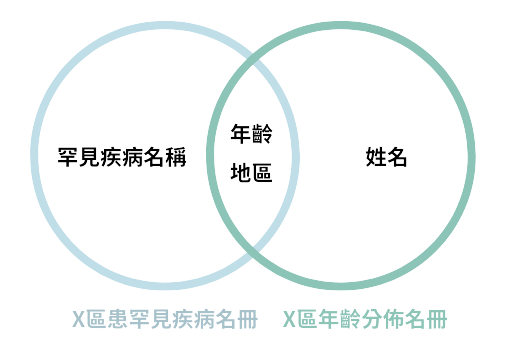
k-匿名化資料集透過外部資料再識別(圖片來源/數位部)
因此,在技術發達的現在,除非資料運用的範圍是可控的,否則並不鼓勵直接釋出 k-匿名化後的資料供他人自由運用。
隱私強化技術並非遙不可及
有鑒於隱私強化技術可以保障資料的隱私,在各種 AI 及資料科學發展的進程中,妥善的應用隱私強化技術更可以加深資料當事人,與非個資數據利用者之間的信任關係。
為了促進各界瞭解隱私強化技術,及降低技術應用的成本,數位發展部已公告「隱私強化技術應用指引」(https://gov.tw/Byk) 、發展「資料共享分析之隱私保護開源方案」,並規數位劃公共建設,為政府機關建立跨領域資料安全鏈結及增強隱私防護,以降低各界應用隱私強化技術的門檻。
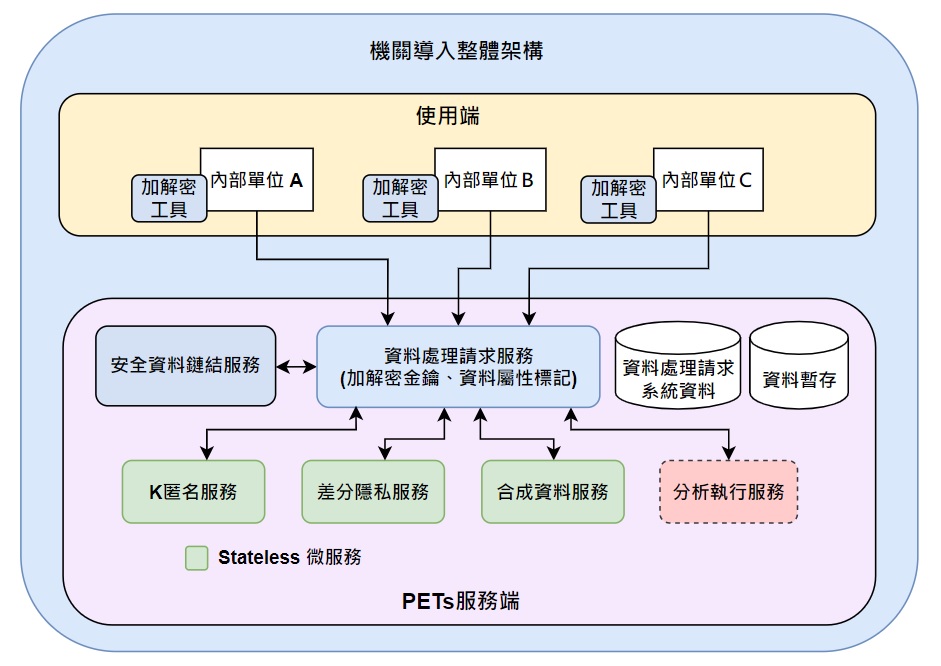
資料共享分析之隱私保護開源方案架構圖(圖片來源/數位部)
「資料共享分析之隱私保護開源方案」的設計目的,是解決單位間分享資料的障礙,以解決業務痛點的應用情境。它可以從 2 個環節來保護隱私:
●多個單位的敏感資料,可以藉由基本的隱私保護措施(例如假名化或是加密技術)匯集,避免直接提供未經處理的直接、間接識別欄位。
●運用差分隱私、合成資料等方式,來進行匿名化及資料最小化,並保留這些非個資數據的分析特徵,代替原始資料進行後續的資料洞察。
需要注意的是,在原始資料經過隱私強化處理的過程中,為保障資料機敏性而加入的雜訊、資料泛化的程度、刪除的離群資料及生成的人造資料等,都將影響衍生資料與原始資料間的差距,也連動資料隱私保護力與後端資料應用的準確性。
在全球發展資料驅動治理及 AI 創新的趨勢下,資料是數位轉型的核心,面對龐大資料應用需求,除呼籲資料處理仍須符合法律規範、公平及透明原則外,更建議進一步認識各種隱私強化技術、了解其效益及限制,並視使用情境擇定合適技術,互相搭配並予以驗證,確認資料可用性及保護力,以平衡資料保護與資料應用需求,進而建構公眾信任之資料創新環境,加速資料生態的共榮發展,促進社會發展、福國利民。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10