
這些年來,在設計和架構方面一直存在不少的疑惑。到底什麼是設計(design)?什麼是架構(architecture)?兩者有何區別?
什麼是設計與結構
對於初學者而言,我會這樣說,他們之間沒有區別。一點也沒有。
「架構」這個詞經常被使用在高層次的事物中,與較低層次的細節脫節,而「設計」往往似乎隱含了較低層次的結構和決策。但是當你看到一個真正的架構師在做什麼時,這個分法是荒謬的。
來看看設計我的新家的建築師。這個家有一個架構嗎?當然有。那麼架構是什麼呢?就是家的形狀(shape);外觀、挑高和空間及房間的佈局。但當我瀏覽我的設計師製作的圖樣時,我看到了大量的低層次細節。我看到每個插座、燈的開關和燈將被放置在哪裡。我看到哪些開關控制著哪個燈。我看到爐子放在哪裡,熱水器和水池泵的大小和位置。我看到了如何建構牆壁、屋頂和地基的詳細描述。
總之,我看到了支持所有高層決策的全部細節。
我也看到,這些低層次的細節和高層次的決策都是房子整體設計的一部分。
因此,這是軟體設計。低層次的細節和高層次的結構都是同一個整體的一部分。它們形成了一個連續的結構,定義了系統的形狀(shape)。你不能只有一個而沒有另一個;事實上,沒有明確的分界線。只有從最高層到最低層的一系列決策。
目標
這些決策的目標是什麼?好的軟體設計的目標是什麼?這個目標不亞於我的烏托邦描述:
軟體架構的目標是最小化建置和維護『需求系統』所需要的人力資源。
設計品質的度量標準,只不過就是度量滿足客戶需求所花的精力(effort)。如果這種精力是少的,並且在系統的整個生命週期中,都保持是少的,那麼這個設計就是好的。如果這種精力會隨著每個新版本的增長而增長的話,那麼這個設計就是不好的,就是那麼簡單。
案例研究
作為一個案例,下面這個案例研究是希望保持匿名的一間真實公司的真實數據。
首先,看看工程人員的增長。我相信你會同意這個趨勢是非常令人鼓舞的。像圖1.1所顯示的增長一定是成功的記號!
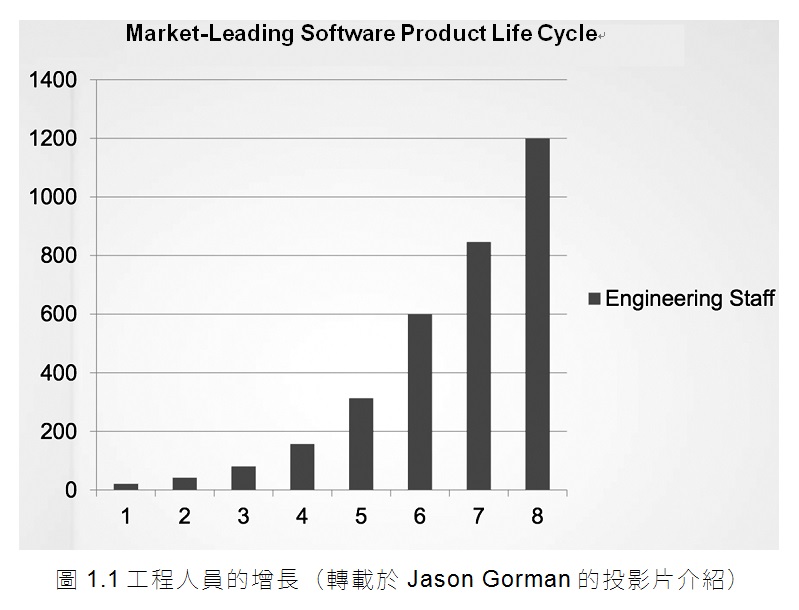
現在,讓我們來看看同一時期的公司生產力,我們用簡單的程式碼行數做為度量標準(圖1.2)。
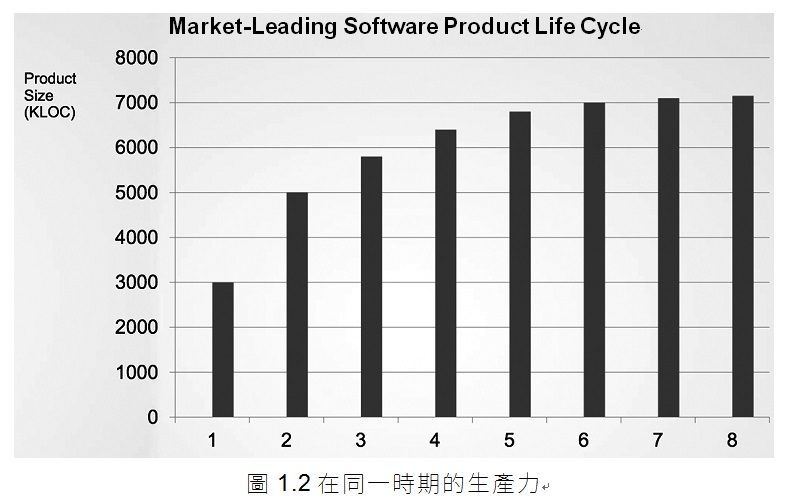
顯然,這裡有點問題。儘管每個發佈版本都有越來越多的開發人員支援著,但程式碼的增長看來逐步漸近了。
下面才是真正可怕的圖表:圖1.3顯示了每行程式碼的成本隨時間變化的情況。
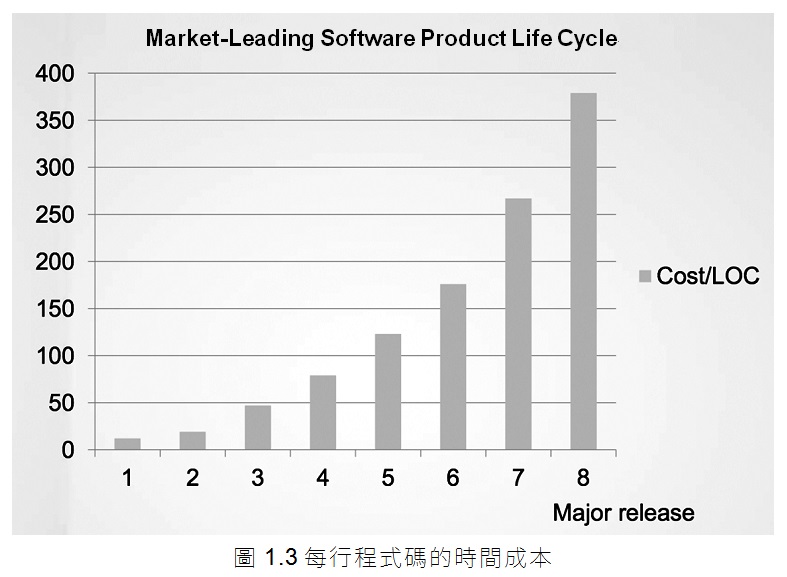
這種趨勢是無法持續的。這個公司此刻的盈利狀況並不重要:這些曲線將大大地消耗這個商業模式的利潤,並將公司推入困境(如果還沒徹底崩潰的話)。
是什麼造就了生產力的顯著變化?為什麼發佈版本8與發佈版本1相比,程式碼的成本要高出40倍呢?
爛攤子的記號
你看到的是一個爛攤子的記號。當系統匆匆被丟在一起時,當程式設計師的數量成為輸出的唯一驅動者,當對程式碼的整潔程度或設計的結構沒有多少想法時,那你就會跟著這條曲線走到最終的悲慘結局。
圖1.4展示了這條曲線對於開發者來說的樣子。他們的生產力幾乎達到了100%,但每次發佈時,他們的生產力都降低了。到了第四次發佈時,顯然,他們的生產率將逐漸降到0。
從開發者的角度來看,這是非常令人沮喪的,因為每個人都在努力工作。沒有人減少他們的努力。

然而,儘管所有的英雄加了班也奉獻了精力,但他們根本不會得到任何東西了。他們所有的努力都不再是開發新的功能特性(feature),現在這些努力是用來管理這個爛攤子的。他們的工作已經改變了,是用來將這個爛攤子從某個地方轉移到另一個地方、下一個和下下個地方,這樣他們就可以再增加一個小小的功能特性(feature)。
高層管理的觀點
如果你認為這是不好的,想像一下這張照片對於高層管理人員來說代表著什麼意義!看看圖1.5,它描繪了同時期的月開發薪資。
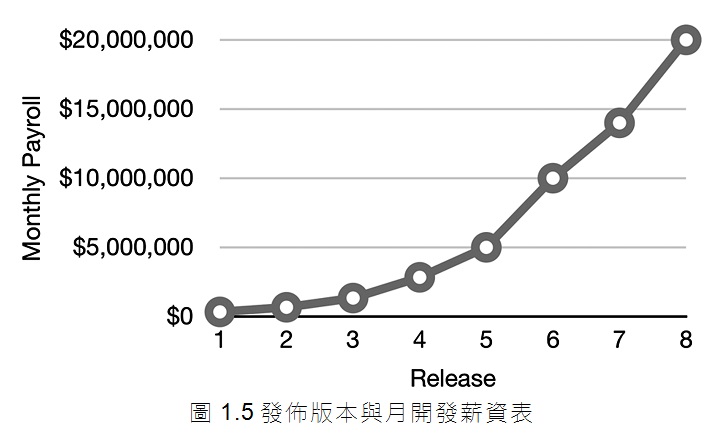
第一個版本的每月花費是數十萬美元。第二個版本則花費了多一點的數十萬美元。但到了第八次發佈時,每月花在薪資上的花費為2000萬美元,並仍在持續攀升。
只有這張圖表是可怕的。顯然有一些驚人的事情正在發生。人們希望收入高於成本,如此才能證明費用的合理性。但是不論你怎麼看這條曲線,它都值得關注。
但現在我們比較圖1.5的曲線及圖1.2中每個版本的程式碼行。最初每月幾十萬美元換得了許多功能──但最後的2000萬美元幾乎沒得到任何東西!任何財務長都會看這兩個圖表,並知道為了避免災難立即採取行動是必要的。
但是,能採取什麼行動呢?這裡出了什麼問題?是什麼導致了生產力如此驚人地下降?高層管理人員若不是只會對開發人員感到憤怒,還能做些什麼呢?
什麼地方出了錯?
在二千六百年前,伊索告訴我們「龜兔賽跑」的故事。這個故事的寓意已經被以許多方式陳述多次了:
● 踏實和穩定持續是贏得比賽的關鍵。
● 這場比賽不是比迅速,也不是比誰較為強壯。
● 越快的,反而速度越慢。
這個故事本身說明了過度自信的愚蠢。兔子對於自己內在的速度如此自信,又不認真對待比賽,所以在烏龜穿越終點時還在睡午覺。
現代開發者也處於類似的競賽狀態,表現出類似的過度自信。哦,他們不睡覺──一點也不。大多數的現代開發人員工作得很努力。但是他們大腦的一部分確實是在睡覺──那些知道好的、整潔的、精心設計的程式碼很重要的那部分腦袋還在睡覺。
這些開發人員常陷入一個熟悉的謊言:「我們可以晚點整理它,但我們只能先上市!」當然,事情之後永遠都不會被清乾淨,因為市場壓力永遠不會減少。首先,進入市場就意味著現在你後面已經有了一大批競爭對手,你必須盡可能快點跑到最前面。
所以開發人員決不會切換模式。他們不能回頭清理,因為他們必須完成下一個功能特性,下下個,下下下個,下下下下個。所以這個爛攤子就此產生,生產力繼續朝著0的方向趨近。
就像兔子對於牠的速度過於自信那樣,開發者對於自己的生產力也過於自信。但程式碼的瑣碎紊亂使得他們的工作效率不彰,這種情況從不停止也不會減緩。如果按照這樣的方式,在幾個月內生產力就會降低到0。
開發人員陷入的另一個更大的謊言是,編寫紊亂的程式碼可以使他們在短期內走得更快,只有長期下來才會變慢。接受這種謊言的開發人員表現出兔子過分自信的能力,認為他擁有在未來將模式從製造紊亂轉為清理紊亂的能力,但這也犯了一個事實上的低級錯誤。事實是,無論你使用的是哪種時間尺度,製造紊亂的開發速度總是比保持整潔的開發速度還要慢。
考慮圖1.6中Jason Gorman所做的一個非凡的實驗結果。Jason用了六天來進行了這個測試。
他每天都完成一個簡單的程式,將整數轉換成羅馬數字。當他預定的驗收測試通過時,他知道他的工作已經完成。每一天的任務花不到30分鐘。Jason在第一天、第三天和第五天使用了一個名為測試驅動開發(TDD,test-driven development)的著名整潔原則。在另外三天,他寫程式時沒有遵守這個原則。
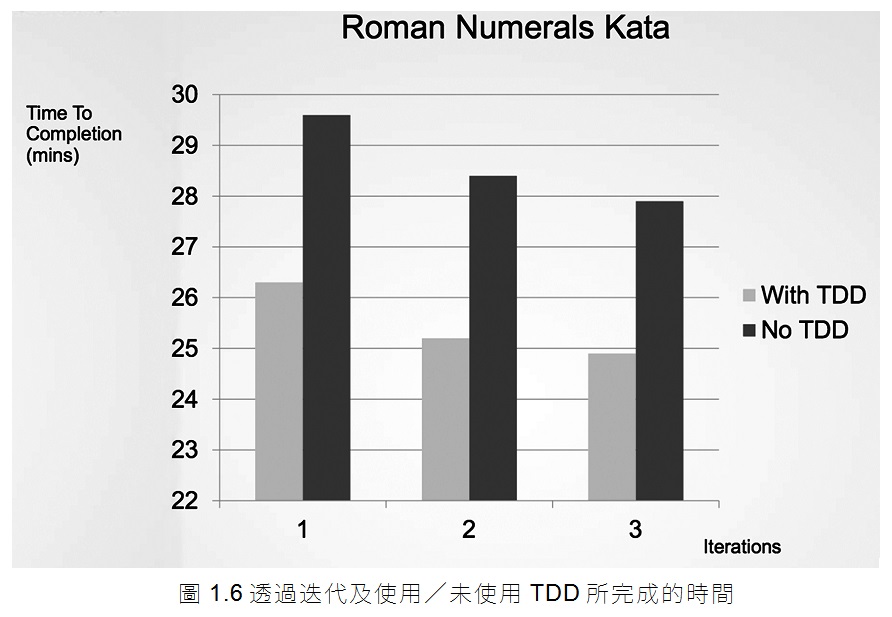
首先,請注意圖1.6的學習曲線。後一天的工作比之前的更快完成。另外請注意,TDD日的工作比非TDD日的工作快了近10%,即便是最慢的TDD日也比最快的非TDD日還要快。
有些人可能會看到這樣的結果,並認為這個分析是一個了不起的成果。但對那些沒有被兔子過度自信迷惑的人來說,這樣的結果是可以預料到的,因為他們知道軟體開發的這個簡單道理:
想要走得快,唯一的方式就是要走得好
這就是高層管理人員困境的解答。扭轉生產力下降和成本增加的唯一方法是,讓開發人員停止像過度自信的兔子那樣思考,並開始為他們所做的紊亂負責。
開發人員可能會認為答案是從頭開始重新設計整個系統但這只不過是兔子再次發言。導致紊亂的那種過度自信現在告訴他們,如果他們能夠重新開始,那麼他們就能好好地建立它。但現實並不樂觀:
他們的過度自信將驅使進行重新設計,就像原來的專案那樣紊亂。
總結
在任何情況下,最好的選擇是讓開發部門認識和避免自己的過度自信,並認真對待軟體架構的品質。
要認真對待軟體架構,你需要知道什麼是好的軟體架構。為了建置一個能『滿足付出精力最小化及生產力最大化』的系統設計和架構,你需要知道系統架構當中的哪些屬性會引領出這個結果。
物件導向程式設計
正如我們將看到的,一個好的架構的基礎是對於物件導向原理的理解與應用。但物件導向(OO)是什麼呢?
對這個問題的一個答案是「資料和函式(功能)的結合」。雖然經常被引用,但這是一個非常不令人滿意的答案,因為它意味著o.f()與f(o)有某些不一樣的地方。而這是荒謬的。程式設計師早在1966年以前,就把資料結構傳遞給了函式,當時Dahl和Nygaard將函式呼叫堆疊框架(stack frame)移到了累堆(heap)中,並發明了OO。
這個問題的另一個常見答案是「一種模擬真實世界的方式」。這只是一個迴避式的答案。「建模真實世界」究竟是什麼意思,為什麼那是我們想要做的事呢?也許這個陳述的意思是在暗示OO使得軟體更容易理解,因為它與真實世界有著更密切的關係──但即使是這樣的說法,也是在迴避問題和給予過於鬆散的定義。它還是沒有告訴我們,什麼是OO。
有些人回頭找了三個神奇的詞來解釋物件導向的本質:封裝(encapsulation)、繼承(inheritance)和多型(polymorphism)。其含義是:OO是這三件事以適當的方式合成的產物,或者至少OO語言必須支援這三件事。
讓我們反過來,一一檢視這些概念。
封裝?
引用封裝作為OO一部分定義的原因是,OO語言了提供簡單又有效的資料和函式(功能)封裝。因此,可以圍繞一組具有緊密關聯的資料和函式(功能)繪製出一個框。對於框外而言,資料是隱藏的,只有一些函式(功能)是已知的。我們將這個概念看作是一個類別的私有資料成員和公有成員函式。
這個想法當然不是物件導向獨有的。的確,我們在C語言中也擁有完美的封裝。考慮下面這個簡單的C程式:
● point.h
struct Point; struct Point* makePoint(double x, double y); double distance (struct Point *p1, struct Point *p2);
● point.c
#include "point.h" #include#include struct Point { double x,y; }; struct Point* makepoint(double x, double y) { struct Point* p = malloc(sizeof(struct Point)); p->x = x; p->y = y; return p; } double distance(struct Point* p1, struct Point* p2) { double dx = p1->x - p2->x; double dy = p1->y - p2->y; return sqrt(dx*dx+dy*dy); }
point.h的使用者無權存取struct Point的成員。他們可以呼叫makePoint()函式和distance()函式,但他們完全不知道Point資料結構的實作或函式的實作。
這是非OO語言的完美封裝。C語言程式設計師一直在做這種事。我們在標頭檔中宣告資料結構和函式,然後在實作檔中實作它們。我們的使用者從來沒有存取過這些實作檔裡面的元素。
但隨著C++形式的OO出現之後,C的完美封裝就被破壞了。
出於技術原因 ,C++編譯器需要在該類別的標頭檔中宣告一個類別的成員變數。所以我們的Point程式變成了下面這樣:
● point.h
class Point {
public:
Point(double x, double y);
double distance(const Point& p) const;
private:
double x;
double y;
};標頭檔point.h的使用者知道成員變數x和y的相關資訊!編譯器會阻止使用者對它們的存取,但是使用者仍然知道它們的存在。例如,如果這些成員名稱修改了,就必須重新編譯point.cc檔!封裝已被破壞。
的確,封裝被部分修復了,方式是將public,private和protected等關鍵字引入到語言中。然而,這是一種必要的hack手法,也就是編譯器在技術上需要去查看這些在標頭檔裡的變數。
Java和C#只是簡單地廢除了標頭/實作的分拆,也因此更弱化了封裝。在這些語言中,無法將一個類別的宣告(declaration)和定義(definition)分離。
基於這些原因,我們很難接受OO是依賴在強封裝之上。事實上,許多物件導向語言很少或根本沒有強制性封裝。
OO的確依賴於一個前提,就是程式設計師必須具備『不會設法迴避資料封裝』的相關良好行為。即便如此,那些聲稱提供OO的語言,也只是減弱了我們曾經一度在C裡頭享有的完美封裝。
繼承?
如果OO語言沒有給我們更好的封裝,那麼他們肯定會給我們繼承。
好樣的。繼承就是在一個封閉範圍內重新宣告一組變數和函式。而這是C程式設計師在OO語言之前就能手動完成的事。
除了原來的point.h之外,讓我們來看看另一個C程式:
● namedPoint.h
struct NamedPoint; struct NamedPoint* makeNamedPoint(double x, double y, char* name); void setName(struct NamedPoint* np, char* name); char* getName(struct NamedPoint* np);
● namedPoint.c
#include "namedPoint.h" #includestruct NamedPoint { double x,y; char* name; }; struct NamedPoint* makeNamedPoint(double x, double y, char* name) { struct NamedPoint* p = malloc(sizeof(struct NamedPoint)); p->x = x; p->y = y; p->name = name; return p; } void setName(struct NamedPoint* np, char* name) { np->name = name; } char* getName(struct NamedPoint* np) { return np->name; }
● main.c
#include "point.h" #include "namedPoint.h" #includeint main(int ac, char** av) { struct NamedPoint* origin = makeNamedPoint(0.0, 0.0, "origin"); struct NamedPoint* upperRight = makeNamedPoint (1.0, 1.0, "upperRight"); printf("distance=%f\n", distance( (struct Point*) origin, (struct Point*) upperRight)); }
如果你仔細看看main主程式,你會發現NamedPoint資料結構就好像它是Point資料結構的衍生資料結構一樣。因為NamedPoint的前兩個欄位的順序與Point相同。簡而言之,NamedPoint可以偽裝成Point,因為NamedPoint是Point的一個純超集合,並且維護了與Point對應的成員順序。
在物件導向出現之前,這種欺騙是程式設計師的慣用手法 。事實上,這樣的詭計正是C++實作單一繼承的方式。
因此我們可以說,在OO語言發明之前就已經有了一種繼承。但是,這個說法不完全正確。我們用了一個技巧,但它不如真正的繼承方便。而且透過這種欺騙想要實現多重繼承是相當困難的。
另外還要注意,在main.c當中,我被迫將NamedPoint參數(arguments)轉型為Point型態。在一個真正的OO語言中,這種向上轉型是隱式的(implicit)。
可以這麼說,雖然OO語言沒有給我們帶來一些全新的東西,但它確實使資料結構的偽裝變得更方便。
回顧一下:在封裝方面,OO可說是一點貢獻都沒有,而在繼承方面,則有半分貢獻。到目前為止,這不是一個很好的分數。
但還有一個屬性要來檢視。
多型?
在OO語言出現之前,我們是否曾有過多型行為?當然,我們有。考慮下面這個簡單的C語言的copy程式。
#includevoid copy() { int c; while ((c=getchar()) != EOF) putchar(c); }
getchar()函式從STDIN中讀取資料。但是哪個設備是STDIN?putchar()函式寫入資料到STDOUT。但那是哪一個設備?這些函式是多型的(polymorphic)──它們的行為取決於STDIN和STDOUT的型態。
就像STDIN和STDOUT是Java風格的介面那樣,每個設備都有對應的實作。當然,在範例C程式中沒有介面,那麼呼叫getchar()時,實際上需要做什麼,才能將任務交付給讀取字元的設備驅動程式呢?
這個問題的答案非常簡單。UNIX作業系統要求每個IO設備驅動程式必須提供五個標準函式 :open,close,read,write和seek。這些函式的署名(signature)對於每一個IO驅動程式而言,都必須一致。
FILE資料結構包含五個函式指標。在我們的例子中,它可能看起來像下面這樣:
struct FILE {
void (*open)(char* name, int mode);
void (*close)();
int (*read)();
void (*write)(char);
void (*seek)(long index, int mode);
};主控台(console)的IO驅動程式將定義這些函式,並將它們的位址載入到FILE資料結構,如下所示:
#include "file.h"
void open(char* name, int mode) {/*...*/}
void close() {/*...*/};
int read() {int c;/*...*/ return c;}
void write(char c) {/*...*/}
void seek(long index, int mode) {/*...*/}
struct FILE console = {open, close, read, write, seek};現在,如果STDIN被定義為FILE*,並且指向了console資料結構,那麼getchar()就可以如下實作:
extern struct FILE* STDIN;
int getchar() {
return STDIN->read();
}換句話說,getchar()只是呼叫由STDIN指向的FILE資料結構的read指標所指向的函式。
這個簡單的技巧是物件導向裡所有多型的基礎。例如在C++中,類別中的每個虛擬函式都會在一個名為vtable的表格中,擁有一個指標,所有對於虛擬函式的呼叫都是透過該表完成的。
那些衍生類別的建構函式只是將屬於它們版本的這些函式,載入到正在建立的物件的vtable之中。
結論是『多型是指向函式的指標』的一種應用。自從Von Neumann架構在1940年代後期首度被實作之後,程式設計師一直在使用函式指標來實現多型行為。換句話說,OO並沒有提供任何新東西。
啊,但這並不完全正確。OO語言可能沒有給我們帶來多型,但OO語言使得多型更安全和更方便。
顯式使用函式指標來建立多型行為引發的問題是,指向函式的指標是危險的。這種使用方式是基於一系列手動約定才得以達成的。你必須記得遵循約定來初始化這些指標。你必須記得按照約定透過這些指標來呼叫你所有的函式。如果任何程式設計師沒有記住這些約定,那麼由此產生的bug可能會很難追查和消除。
OO語言消除了這些約定,進而也排除了這些危險。使用OO語言使得多型變得很簡單。這個事實提供了C語言的老程式設計師只能在夢中才能取得的巨大力量。在此基礎上,我們可以得出結論,OO在間接的控制移轉上加上了規範。
多型的威力
多型有什麼好處?為了能好好地欣賞它的魅力,讓我們重新檢視copy程式範例。如果建立一個新的IO設備,該程式會發生什麼事?假設我們要使用copy程式將資料從手寫識別設備複製到語音合成設備:我們需要如何更改copy程式才能使用這些新的設備?
我們根本不需要作任何改變!事實上,我們甚至不需要重新編譯copy程式。為什麼呢?因為copy程式的原始碼不依賴IO驅動程式的原始碼。只要這些IO驅動程式實作了FILE定義的五個標準函式,copy程式將樂於使用它們。
簡單說,IO設備已經成為copy程式的plugin(外掛)。
為什麼UNIX作業系統要讓IO設備成為plugin?因為我們在1950年代後期了解到,我們的程式應該要獨立於設備。為什麼呢?因為我們編寫了很多依賴於設備的程式之後,卻發現到我們其實是希望那些程式做相同的工作,只是使用不同的設備。
例如,我們經常編寫從一疊卡片讀取輸入資料的程式 ,然後打出新的一疊卡片作為輸出。後來,我們的客戶停止給我們一疊卡片,開始給我們磁帶。這非常不方便,因為這意味著要重寫大部分的原始程式。如果同一個程式在卡片或磁帶互換時仍舊可以工作,這將是非常方便的。
為了支援這種IO設備的獨立性,plugin架構被發明出來,並且自推出以來幾乎已經在各種作業系統中實作出來了。即便如此,大多數程式設計師並沒有將這種做法延伸到他們自己的程式之中,因為使用函式指標是危險的。
而OO允許plugin架構在任何場合應用於任何事情上。
依賴反向
想像一下,在安全和方便的多型機制可用之前,軟體是什麼樣的。在典型的呼叫樹(calling tree)中,主函式呼叫高層級函式,高層級函式呼叫中層級函式,中層級函式呼叫低層級函式。然而,在那個呼叫樹中,原始碼的依賴關係緊緊跟隨著控制流程(如圖5.1)。
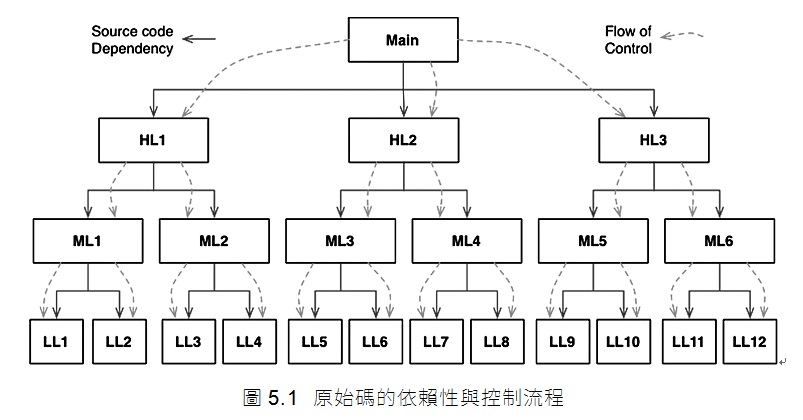
對於main呼叫的其中一個高層級函式而言,在C語言中,它就不得不提及包含該函式的模組名稱,也就是#include。在Java中,這是一個import語句。在C#中,它是一個using語句。事實上,每個呼叫者都被迫『提到』包含被呼叫者的模組名稱。
這個需求使得軟體架構師的選擇變得很少。控制流程是由系統的行為決定的,而原始碼依賴性又是由控制流程決定的。
然而,當多型發揮作用時,可能會出現很多不同的事(圖5.2)。
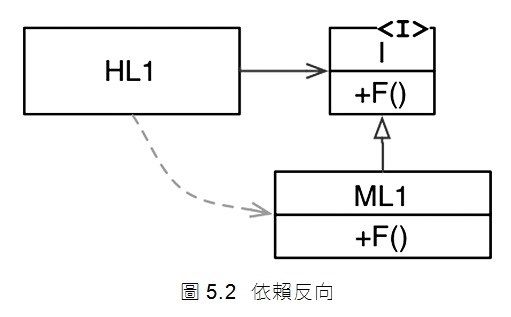
在圖5.2中,模組HL1呼叫模組ML1當中的F()函式。原始碼使用了一個特殊技巧,事實上,它是透過介面來呼叫這個函式的。在執行期間,該介面並不存在。HL1只是簡單地呼叫了ML1中的F() 。
但是請注意,相較於控制流,ML1和介面I之間的原始碼依賴關係(繼承關係)是相反方向的。這就是所謂的依賴反向(dependency inversion),並且依賴反向對於軟體架構師來說,產生了深刻的影響。
事實上,OO語言提供的安全且方便的多型意味著,無論在何處,任何的原始碼依賴都可以被反向。
現在回頭來看看圖5.1的呼叫樹,以及當中的許多原始碼依賴關係。任何原始碼的依賴關係都可以透過在它們之間插入介面來解決。
應用這種方式,軟體架構師若工作於以OO語言編寫的系統,就能夠絕對控制(absolute control)系統中所有原始碼依賴的方向。他們在這些依賴關係與控制流的對應上,不會被限制住。無論是呼叫哪個模組或是哪個模組被呼叫,軟體架構師都可以在原始碼的依賴性上指定任何方向。
這就是力量!這就是OO提供的威力。這就是OO的真正意義(至少從架構師的角度來看正是如此)。
你能利用這種力量做什麼呢?舉例來說,你可以重新排列系統的原始碼依賴關係,以便資料庫和使用者界面(UI)依賴於業務規則(如圖5.3),而不是其他的依賴方式。

這意味著UI和資料庫可以做為業務規則的plugin。這意味著業務規則的原始碼永遠不會提及UI或資料庫。
因此,業務規則、UI和資料庫可以被編譯成與原始碼具有相同依賴性的三個獨立元件或部署單元(例如,jar檔、DLL或Gem檔)。包含業務規則的元件將不依賴於包含UI和資料庫的元件。
反過來,業務規則可以在UI和資料庫之外獨立進行部署(deployed independently)。UI或資料庫的變更不會對業務規則產生任何影響。這些元件可以分別和獨立地部署。
簡而言之,當元件中的原始碼發生變化時,只有該元件需要進行重新部署。這就是可獨立部署性(independent deployability)。
如果系統中的模組可以獨立部署,那麼就可以由不同的團隊來獨立開發。這就是可獨立開發性(independent developability)。
總結
什麼是OO?這個問題有很多種看法以及很多的答案。但對於軟體架構師來說,答案很明顯:OO是透過使用多型,來獲得對於系統中每個原始碼依賴方向的絕對控制力。它允許架構師建立一個plugin架構,其中,包含策略的高層級模組獨立於包含細節的低層級模組。低層級的細節被放到plugin模組當中,這些plugin模組可以獨立於包含高層級策略的模組來進行部署和開發。(摘錄整理自《無瑕的程式碼:整潔的軟體設計與架構篇》)
無瑕的程式碼:整潔的軟體設計與架構篇
Robert C. Martin/著;林欣穎/譯;陳錦輝/審校
博碩文化出版
售價:580元
作者簡介
Robert C. Martin
人稱Uncle Bob,程式設計經驗超過40年,Agile Software(敏捷軟體開發)的提倡者之一。創立Object Mentor,這是一間專注於C ++、Java物件導向、模式、UML、敏捷方法學和極限程式設計的顧問諮詢公司。
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
2026-02-09
")
")
2026-02-09
