
MosaicML團隊修改了熱門的DeepMind Chinchilla優化方法,來根據理想的模型品質和運算成本需求,計算出最佳的LLM參數量與訓練資料集大小,並實際用Chinchilla模型來實驗。
MosaicML
重點新聞(1229~0104)
LLM Chinchilla 擴展法則
突破LLM擴展法則?MosaicML揭新研究成果
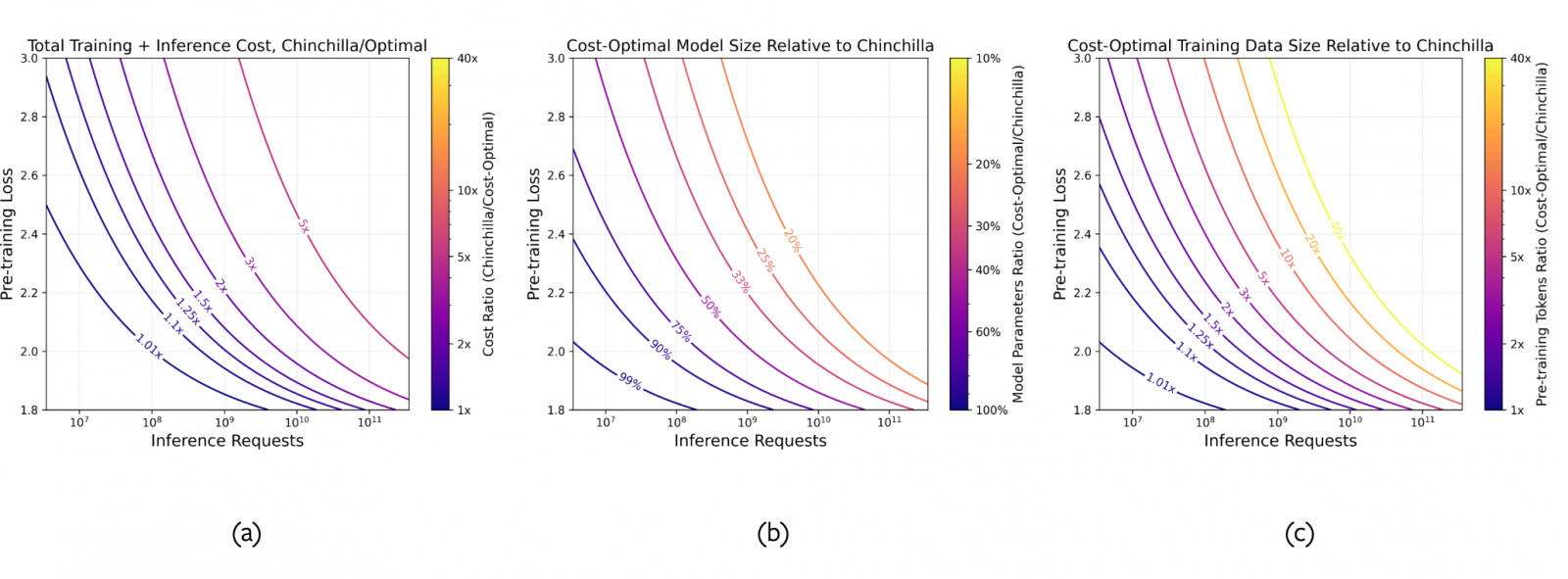
一般來說,LLM擴展法則都是以模型參數量和訓練資料量,來估算模型品質的變化,就連熱門的DeepMind Chinchilla(龍貓)優化方法也是。換句話說,這個法則是指,模型的訓練Token數和參數越多,模型表現理應越好。
但MosaicML團隊認為,這些公式忽略了模型推論成本。因此,他們修改了DeepMind的Chinchilla擴展法則,來根據目標,即理想的模型品質和運算成本需求,計算出最佳的LLM參數量與訓練資料集大小。他們的公式建議,可使用更少參數的模型,但以比Chinchilla優化方法更長的訓練時間,來訓練模型,一樣可實現高品質模型。
這項研究也實驗發現,Chinchilla模型在高推論需求下,可用更少的參數和更多資料,來進行優化訓練,還能大幅降低總運算成本,從70億參數、130億參數和700億參數的模型版本都是。該研究也討論了TinyLlama,這是一個11億參數的輕量版模型,使用了3兆個Token訓練而成,MosaicML表示,這是突破Chinchilla擴展法則的另一例,特別是當推論需求越接近訓練資料大小時,這股趨勢越明顯。不過,團隊也表示,他們的公式還需要進一步驗證適用性,特別是在預訓練Token數明顯超過模型參數的情形下。(詳全文)
摩根大通 DocLLM 多模態
摩根大通發表懂圖文的輕量級多模態模型DocLLM
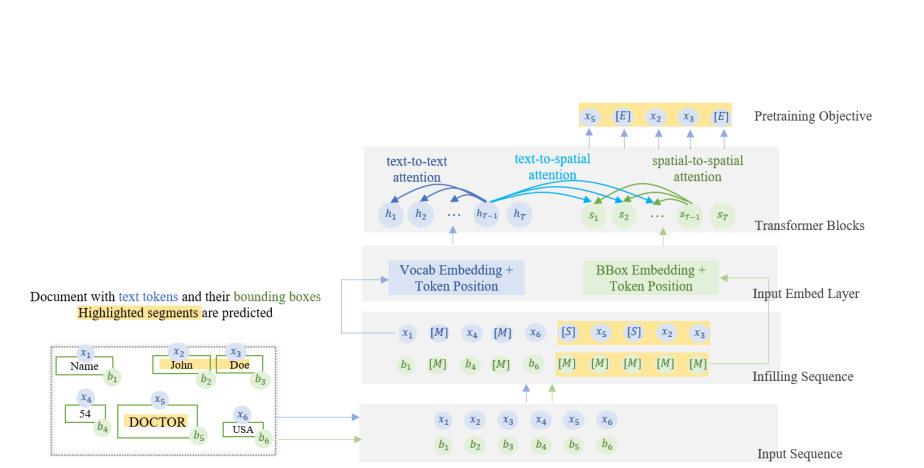
日前,摩根大通發JPMorgan表自行研發的多模態輕量級語言模型DocLLM,可用來分析企業文件,如發票、收據、合約、表格和報告等。進一步來說,DocLLM使用OCR得到的邊界框,來添加空間位置資訊,因此不必使用複雜的視覺編碼器,減少處理時間。這麼做,幾乎不增加模型大小,也保留了因果解碼器的架構。
團隊表示,他們的方法將空間資訊與文字資訊分離,能將典型的Transformer自我注意力機制擴展,來捕捉跨模態的互動資訊。由於文件中常出現碎片化的文字區塊和複雜版型,為解決辨識問題,團隊還在自監督預訓練階段,改變預訓練目標,利用填充方式來適應各種文字排版和區塊,模型也能更有效處理混合型或文字不對齊的文件。經測試,DocLLM在16個資料集中的14個,表現比同類模型要好,如Llama 2加上OCR。目前,摩根大通尚未釋出任何DocLLM程式碼或資料集,僅發表論文。(詳全文)
TinyGPT-V 多模態 Phi-2
研究員開源28億參數多模態小模型TinyGPT-V
最近,來自美國理海大學、新加坡南洋理工大學和中國安徽大學的研究者共同發表一款28億參數的多模態模型TinyGPT-V,號稱表現比與70億參數和130億參數版本的Flamingo、MiniGPT-4和其他多模態大型語言模型(MLLM)還要好,所需運算成本也更低。
TinyGPT-V以微軟的小型語言模型Phi-2為骨幹,並整合了BLIP-2或CLIP這類的預訓練視覺模組,只需要24GB的GPU進行訓練、用8GB的GPU或CPU就能進行推論。經測試,TinyGPT-V在視覺空間推理(VSR)零樣本任務的表現優異,比其他大參數型的同類模型表現要好。此外,研究團隊表示,TinyGPT-V因採用特殊架構,因此可在8GB容量的裝置上進行本地端部署和模型推理工作,可算是MLLM部署難題的另一出路。(詳全文)

金管會 金融業運用AI指引 公平性
金管會發布金融業運用AI指引草案
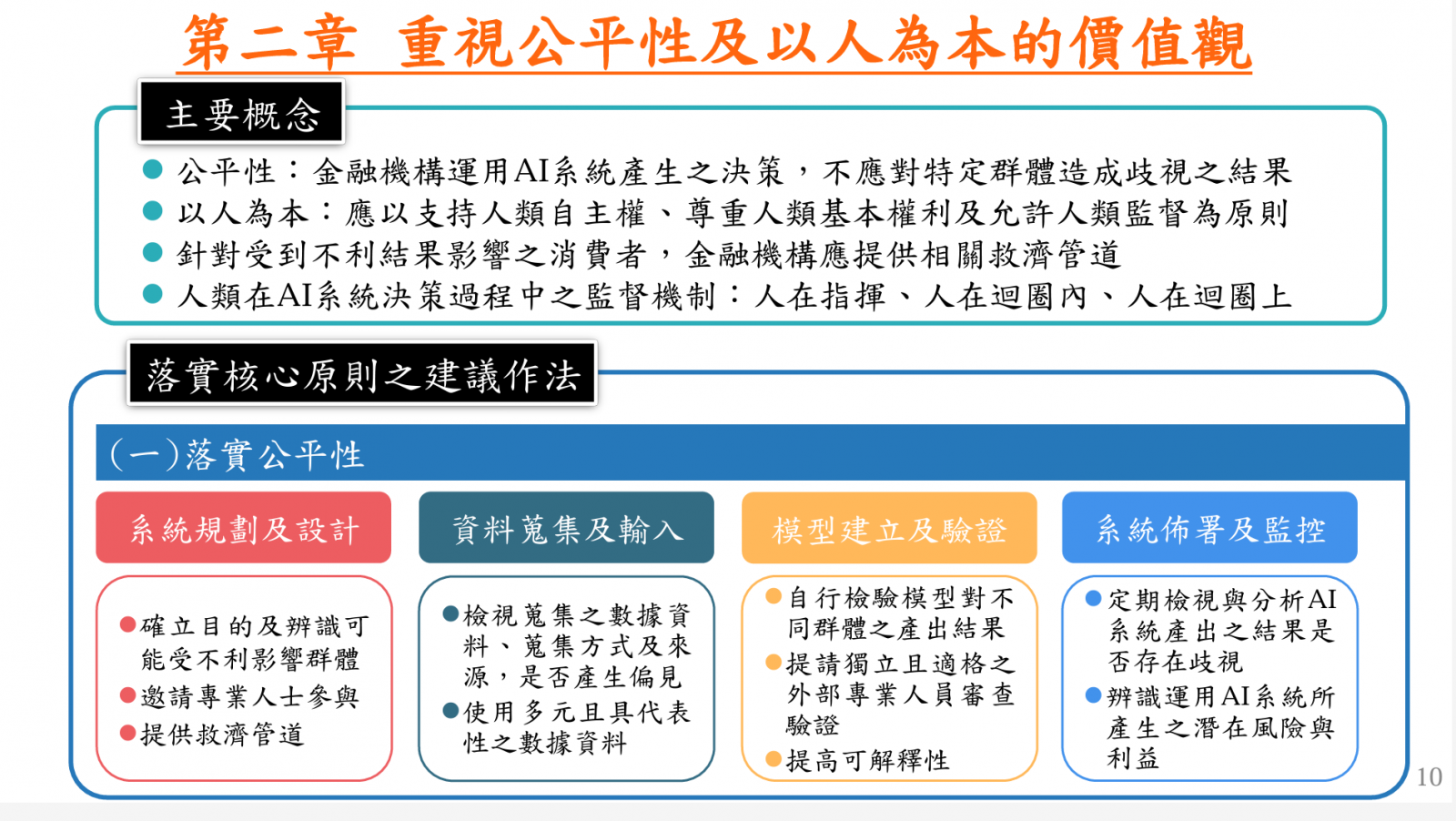
就在上個月底,金管會公布了金融業運用AI指引草案,提供6大原則與建議供金融業者參考。該草案定義了AI系統的4大生命周期階段,包括系統規畫及設計、資料蒐集及輸入、模型建立及驗證,和系統佈署及監控,而草案則建議金融業者,要在各個階段落實核心原則。
這些核心原則包括了建立治理及問責機制、重視公平性及以人為本的價值觀、保護隱私及客戶權益、確保系統穩健性與安全性、落實透明性與可解釋性,以及促進永續發展。以落實公平性為例,指引建議了業者在AI系統4大生命周期階段可採取的措施,比如系統規畫及設計階段,須提供救濟管道,在資料蒐集及輸入階段則要檢視數據是否產生偏見,在模型建立及驗證階段,除了要自行檢驗模型對不同群體產生的結果,還要聘請外部人員驗證。至於系統佈署及監控階段,則要定期檢視、分析AI系統產出的結果是否存在歧視。該草案將對外徵詢意見,自發布日起60日後,將視各界意見修正、正式發布指引。(詳全文)
蘋果 Ferret 多模態
蘋果公布多模態AI模型Ferret
自2023年12月開始,蘋果陸續公布AI研發成果,日前又發布了多模態大型語言模型(MLLM)Ferret和相關基準測試工具與資料集。多模態是指模型可處理多種類型的資料,以Ferret來說,它可接收文字、聲音、影像和數據的輸入值。
這款Ferret採用新式混合區域表徵技術,整合了個別方位和連續性的特徵,來表示圖片中的某一區域。為提取出區域中的連續特徵,蘋果還提出一種空間感知的視覺採樣器,來處理不同形狀多種稀疏性。如此一來,Ferret就可接收多樣化區域輸入,像是點、邊界框或自由形式的形狀。
蘋果用這些方法和資料訓練出Ferret-13B。經測試,與Kosmos-2、GPT4-ROI、LLaVA、Shikra等MLLM相比,在需本地化的多模態對話和細節描述等任務中,Ferret表現都比這些MLLM好。在視覺化比較任務中,Ferret也表現出優異的空間理解和常識推理能力。蘋果還指出,Ferret物件幻覺也比Shikra、InstructBLIP、MiniGPT4、LLaVA、MM-GPT和mPLUG-Owl等知名MLLM少很多。(詳全文)

Google 交通模擬 車輛
Google開發交通模擬模型,成功加速大型活動後車輛離場
Google研究院與西雅圖交通部合作,開發模擬交通引導計畫,還將研究結果實際應用在道路交通上。他們採用數位雙生(Digital Twins)方法,由Google先用開源模擬軟體SUMO,來針對西雅圖體育場周邊地區打造交通模擬模型,盡可能地重現特定時間的交通狀況。同時,團隊還用Google地圖資料,來定義網路結構和各種路段靜態屬性,如車道數、限速和交通號誌等。
接著,他們還將道路網路劃分為不同區域,來計算車行需求,也就是車型數量。後來,團隊使用匿名車行統計資料來校準預測策略,西雅圖警察局也提供了最需改進的擁擠路線,來讓Google用模擬模型評估新路線策略。最後,他們在2023年8月和11月期間,在多個數千名參加者的大型活動中實驗,採用新的路線策略,並以動態訊息號誌(DMS)引導車輛,成功將離開體育場的平均車行時間降低7分鐘。(詳全文)

船隻軌跡 衛星圖像 GPS
靠AI和衛星圖像,畫出全球首張海上船隻足跡地圖
《自然》期刊最近刊出一篇研究報告,全球漁業觀察(Global Fishing Watch)組織主導一項研究,用機器學習和衛星圖像,繪製出全球首張海上基礎設施和船隻足跡地圖,揭露75%的工業漁船一直在暗中活動。
團隊透過衛星圖像、船隻GPS資料和AI模型,來分析2017年至2021年間的2PB衛星圖像。他們訓練了3個模型來辨識衛星圖像的物件,也分析了船隻自動辨識系統的530億個GPS位置,並與衛星偵測結果比對,來確認偵測到的船隻是否可公開追蹤。他們發現,任何特定時間平均可檢測到6.33萬艘船隻,當中近一半為漁船,但有3/4的漁船並未出現在公共偵測系統中,其它種類船隻未出現的比例則是1/4。這代表,全球船隻活動中,有一半的船隻無法被公開追蹤。這項研究顛覆了某些認知,比如以前以為沒有太多船隻活動的海域,其實聚集了大量船隻,或是公開資料顯示歐亞境內的捕魚活動相似,但實際並非如此。(詳全文)
AI評測中心 數位部 公平性
生成式AI加速法律利益衝突檢查
生成式AI也加速法律科技發展,最近,法律科技軟體公司鈦度科技打造一套雲端服務平臺Matteroom,用微軟Azure OpenAI服務,來簡化法律事務作業。比如,使用者可用來強化利益衝突檢查,在案件承接前置作業時,先分析資料庫中龐雜的數據,找出客戶與事務所其他案件的潛在利益衝突與風險排競,來將過往手動搜尋所需的數小時,縮短為幾秒鐘。此外,這款Matteroom也整合了辦公軟體Microsoft 365,能管理自動化出帳、人員績效洞察等作業流程,可節省30%的秘書及會計等行政勞動成本。(詳全文)
圖片來源/MosaicML、Zhengqing Yuan、金管會、蘋果、Google、鈦度科技
AI近期新聞
1. 微軟全面推出Copilot App
2. 英特爾成立生成式AI公司Articul8 AI
3. 高通推出混合實境晶片Snapdragon XR2+
4. 高品質聲音複製模型OpenVoice開源了
資料來源:iThome整理,2024年1月
熱門新聞
2024-04-28
")
2024-04-26
2024-04-26
2024-04-26
2024-04-26
</a>")
2024-04-26