Meta
Meta上周發表可讓用戶使用語音及文字指令生成音效及語音的最新AI模型Audiobox。
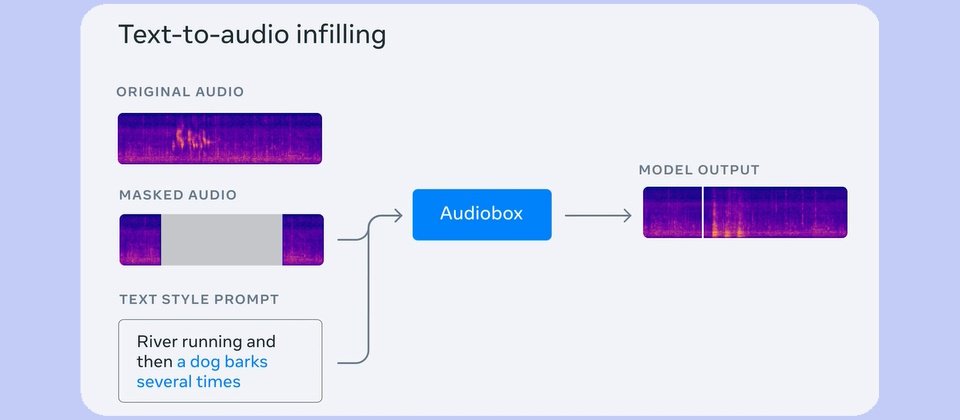
Meta今年6月發表Voicebox AI模型,可應用在語音生成、去噪、採樣和內容編輯等各式語音任務,不限定特定應用場景且具高效能。Audiobox則是Voicebox的後一代模型,以Voicebox框架為基礎開發。Audiobox能生成各種環境及風格的語音、音效或聲音地景(soundscape),新模型整合生成和編輯能力,以及多種輸入機制,以擴大不同應用場景的控制能力。
Audiobox承襲了Voicebox的引導聲音生成訓練目標,以及音流比對(flow-matching)建模方法,以支援聲音填充(audio infilling),以生成或修飾音效,例如在下雨聲音地景加入雷聲。使用者可運用自然語言文字提示描述想要的聲音或語音類型。用戶可輸入「潺潺流水、鳥兒啾啁」的文字提示生成聲音地景,或是以「高聲快節奏講話的年輕女性」生成人聲。該模型還讓使用者輸入人聲及文字提示,以合成任何環境(如教堂)或任何情緒(如哀痛而緩慢)的一段說話。Meta認為Audiobox是第一個可接受語音及文字描述來改造聲音的模型。
.jpg)
經過Meta測試,顯示Audiobox在音質及相關性(切合文字描述的程度)都超越了現有最佳的聲音生成模型如AudioLDM2、VoiceLDM及TANGO。
Meta解釋,生成高品質聲音需要有大量音訊庫及深厚的領域知識,如聲音工程、後製、語音表演等,但大眾和消費者都不會有這些資源。他們推出這個模型,相信未來可降低聲音生成的門檻,讓任何人都更容易製作影片或podcast、電玩或其他應用場景的音效。
Meta即將準備讓特定研究人員及學者專家試用Audiobox,測試模型品質及安全倫理性。再過幾周將透過申請網頁開放申請試用。
Audiobox是Meta發表的AI研發成果之一。為慶祝AI研究中心FAIR成立十周年,Meta還公佈翻譯模型Seamless Communication。此外,Meta也宣布即將公開影像學習及多模感知模型的基礎訓練資料集Ego-Exo4D。Ego-Exo4D是Meta開發VR眼鏡Project Aria並和學界合作的成果,主體為以人為中心(egocentric)及外心(exocentric,由鏡頭環視周遭場景)的資料集,兩種角度能提升AI模型學習人類技能的能力。這批資料包含1,400小時影片及基準模型,將供研究社群使用。
熱門新聞
2024-05-19

2024-05-20

2024-05-18

2024-05-17

2024-05-17


2024-05-20