
nvidia
近兩年來,我們一直持續關注與報導CXL(Computer Express Link)技術的發展,就概念上來說,CXL可說是x86處理器平臺架構的一大革新,透過基於PCIe介面的高速傳輸通道,連結處理器與周邊裝置的記憶體資源,藉此提供異質平臺間的記憶體資源擴展、分享,以至獨立記憶體池等應用型態,進而打破困擾伺服器CPU運算架構已久的兩大問題:記憶體可用頻寬限制,以及記憶體資源利用率瓶頸,最終促成更有效率、運用更靈活的資料中心基礎架構。
而CXL技術的推動,則是在Intel主導下,匯聚當前IT業界幾乎所有領導廠商,也陸續整併其他類似的記憶體互連技術,例如,Gen-Z與OpenCAPI分別在2021年與2022年併入CXL規範。
從應用目標、技術基礎,以及背後的推動力量來看,CXL應該會有很大的發展,但現實卻非如此,遲遲未能出現CXL應用的爆發。
進展緩慢的CXL應用
當CXL聯盟於2019年3月發布CXL 1.0版規範後,接著又陸續於2020年底與2022年中發布CXL 2.0與3.0版規範。
在實際產品方面,過去4年多來,至少已有二十多家廠商陸續發表與展出CXL相關周邊產品與解決方案,涵蓋元件到系統層級。在元件層級方面,已有十多家廠商推出CXL應用涉及的CXL控制器(Controller)、定時器(Retimers)與交換器(Switch)等元件。在系統層級方面,目前應用型態較單純的CXL記憶體擴充模組產品,應用環境已經備妥,至少有5、6家廠商推出產品;較複雜的CXL記憶體池,也已經出現已7、8種頗具吸引力的解決方案。
儘管如此,CXL的應用至今仍未出現顯著的進展。以往我們都是將CXL應用遲滯的原因,歸咎Intel與AMD這兩大處理器平臺廠商,支援CXL的腳步太慢,直到2022年底到2023年初,才分別在第四代EPYC平臺(Genoa),以及第四代Xeon Scalable平臺(Sapphire Rapids),開始支援CXL技術。這也導致CXL的應用環境,呈現周邊產品發展比伺服器平臺更快的現象,無法形成完整的CXL應用生態系。
然而當Intel與AMD推出第一批支援CXL的伺服器平臺,至今過了一年多之久,相關應用的進展仍很有限。我們一開始認為原因在於目前的伺服器平臺,還只支援較基本的CXL 1.1,而不支援應用面向更廣泛的CXL 2.0所致,但問題可能不僅止於此,我們看到有專家提出看法,描述CXL發展困境,例如,日前半導體產業分析師Dylan Patel發表一篇名為〈CXL Is Dead In The AI Era〉的文章,從AI應用崛起、衝擊CXL應用的角度,解讀CXL發展陷入停滯的原因,也點出CXL的未來面臨重大挑戰。
AI帶來的運算環境劇變
Dylan Patel表示,在兩年前,從超大規模平臺到新創廠商,幾乎整個IT業界都在追逐CXL,但是到了現在,許多相關專案都已經擱置,許多廠商悄悄從CXL領域撤出資源。而如同Patel的文章標題所言,他認為正是AI應用在這2年的迅速崛起,導致CXL遭到邊緣化。
原則上,CXL技術也能應用於GPU,有助於擴展GPU的記憶體資源。但Patel認為,CXL最大的困難,在於Nvidia不支援CXL。在Nvidia的運算架構中,是以自身的NVLink與C2C架構作為I/O架構主軸,PCIe只居於次要地位,這也使得建構在PCIe上的CXL應用,難有發揮的空間。
CXL在Nvidia架構中無從發揮
Patel指出Nvidia之所以採用NVLink與C2C作為主要的I/O連接通道,是基於在有限晶片面積內,盡可能獲得最大I/O頻寬的目的所致。
當前GPU發展的重點之一,是整合高頻寬記憶體(HBM),新一代GPU對於HBM記憶體的需求量越來越大,導致HBM記憶體占用了更多GPU晶片的周圍側邊區域——稱為晶片的海濱(beachfront)或海岸線區域(shoreline),因而擠壓了同樣布置於GPU周圍區域的I/O單元可用空間。
以Nvidia的H100來說,在晶片的4個側邊空間中,有整整2個側邊全部都是6個HBM記憶體堆疊單元,而新一代的B200也同樣如此,8個HBM單元佔用了整整2個側邊,因而只剩其餘2個側邊可用於布置I/O單元,這也導致不同類型的I/O介面,必須爭搶這有限的布置空間。
以H100為例,一共支援3種I/O介面:除了通用的PCIe外,還有Nvidia專屬的NVLink與C2C,而Nvidia選擇只為H100配置最低限度的16個PCIe通道,將更多空間用於配置NVLink與C2C。相較下,一般x86 CPU至少都會配置128個PCIe通道。
造成Nvidia如此配置的原因,在於PCIe的頻寬遠不如NVLink與C2C,前者每個方向的頻寬為64 GB/s,而後2者則達到450 GB/s,差距達到7倍,所以為了在有限晶片面積下,獲得最大的傳輸頻寬,優先配置NVLink與C2C,降低PCIe配置,便成為理所當然的選擇。

上圖為Nvidia Blackwell架構的晶片剖圖,可見到在晶片的4個側邊(海濱區域)中,有整整2個側邊都被用來布置HBM記憶體單元,只剩另2個側邊可布置I/O單元,為了在有限晶片側邊面積內,獲得最大的頻寬,Nvidia選擇優先配置頻寬更高的NVLink與NVLink C2C,而只保留最低限度的PCIe介面配置。
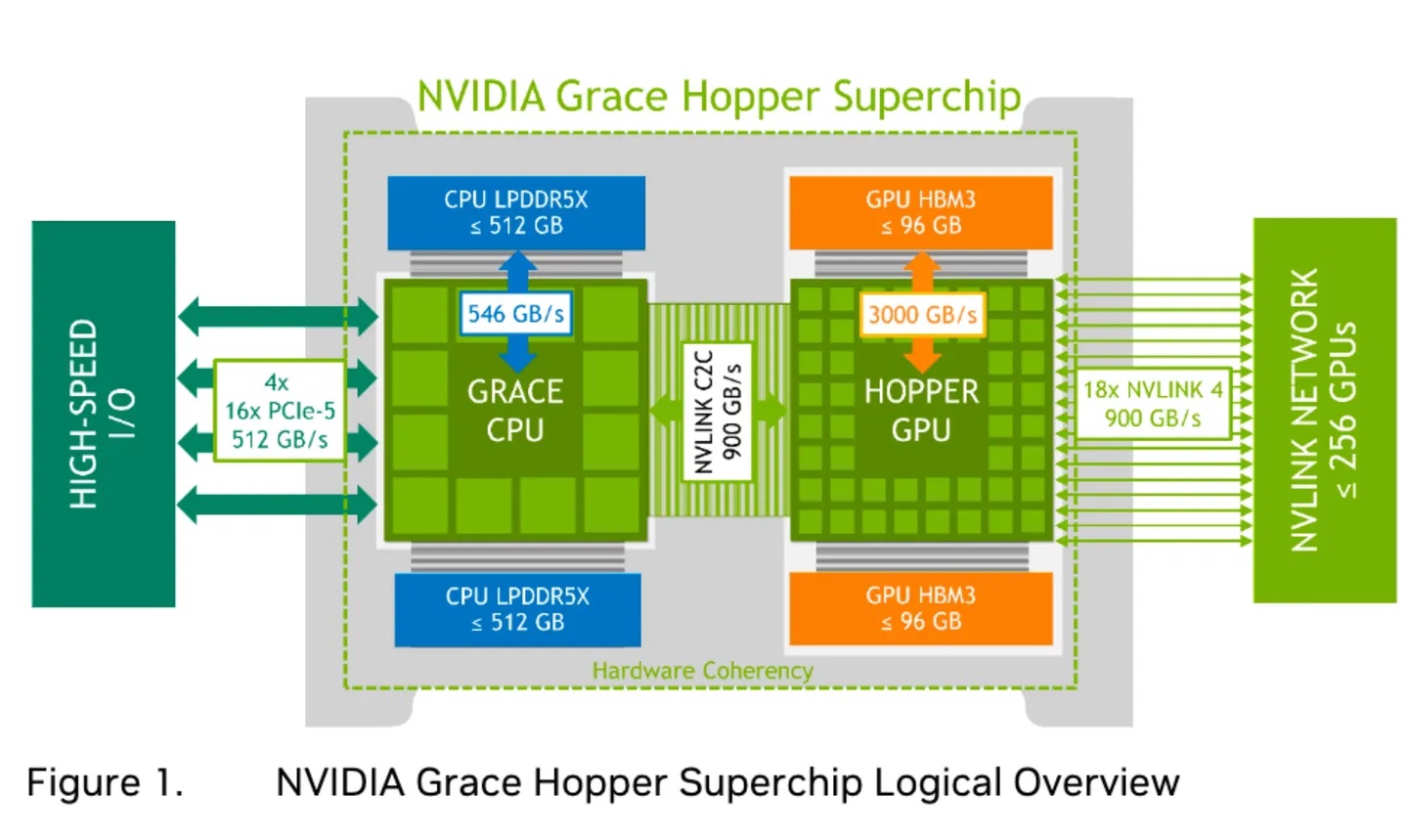
下圖為Nvidia Grace Hopper晶片的I/O架構,可見到在晶片內部,GPU之間與GPU到CPU之間,分別採用NVLink與NVLink C2C介面互連,PCIe只作為次要角色,被用於CPU對外連接,只配置了4組16通道的PCIe 5介面。
圖片來源:Nvidia
PCIe的先天限制
Patel進一步指出,若以單位面積所能提供的頻寬為基準,PCIe 5.0與NVLink/C2C之間的差距,其實只有3倍左右(PCIe每條通道占用的布線面積較小),但兩者間的總頻寬依然差距龐大。
而造成這樣大頻寬差距的原因,是PCIe的SerDes(SERializer/DESerializer序列器與解序器)架構,與NVLink這類乙太網路類型SerDes架構,存在著先天的差異所致。PCIe對延遲的要求遠為嚴苛,連帶也有更嚴格的誤碼率(Bit Error Rate,BER))要求,限制了可用的錯誤修正機制類型,導致錯誤修正資料的處理必須占用更多頻寬。相較下,NVLink這類乙太網路類型SerDes架構,對延遲與誤碼率的要求低了許多,因而也更有利於提高頻寬,固然這會造成較大的延遲,但是這對AI應用的大規模平行作業環境中,影響相對有限。
所以Patel認為,AI運算叢集的主要縱向與橫向擴展I/O介面,都將會是乙太網路類型SerDes架構的協定,如Nvidia的NVLink、Google ICI,或是乙太網路與InfiniBand,而不會是PCIe類型的SerDes架構,這也是CXL應用陷入困境的根本原因。
Patel指出,目前在AI運算晶片領域只有AMD的MI300A APU支援CXL,但MI300將較多晶片周邊區域面積用於配置PCIe式SerDes架構的結果,雖然提供更多連接彈性,卻也限制了可用頻寬。
AI衝擊下的CXL發展前景
Patel提出的觀點給了我們很大的啟發!隨著AI應用的崛起,GPU已經取代CPU,成為驅動資料中心運算能力成長與架構變革的主要力量,整個應用需求大幅倒向GPU領域,連帶也讓CXL技術原本所要解決的問題——伺服器CPU記憶體頻寬與利用率受限,成為相對次要的問題。
當AI興起導致主要運算負載轉移到GPU端後,CPU端的記憶體頻寬與資源運用問題,已不再那樣迫切,而CXL所欲建構的獨立記憶體池、異質運算共用記憶體環境等目標,同樣也不再那樣有吸引力。
儘管由於與周邊裝置溝通的需求,GPU仍會保留PCIe,但像Nvidia這樣採取最低限度的PCIe配置,恐怕會成為常態,這也使得建構在PCIe上的CXL,可發揮的舞臺空間受到大幅限縮。所以如Patel所言,在AI興起的時代,CXL重要性將有顯著的降低。
更進一步,當GPU重要性大幅提高後,由於Nvidia在GPU領域具有壟斷市場的地位,也讓Nvidia的運算框架主導了資料中心的運算核心型態。Nvidia青睞的I/O介面,如NVLink與C2C,自然也成為主流,除了廠商建立技術壁壘的因素,NVlink與C2C的架構與效能確實也有優勢。即便未來PCIe/CXL升級到PCIe 6與CXL 3.0,但Nvidia也已備妥新的第5代NVLink,它們之間依然存在3倍頻寬差距。
不過,相對而言,當NVLink這種個別廠商專屬技術,佔據整個業界的運算I/O架構主流時,恐怕對業界的長遠發展也會有不利的影響。最理想的發展,是發展出適用於AI應用的開放式I/O架構,這或許也會給CXL留下一定的發展空間。
熱門新聞

2023-12-03

2024-04-24


2024-04-25

2024-04-26
2024-04-22

2024-04-22

2024-04-22