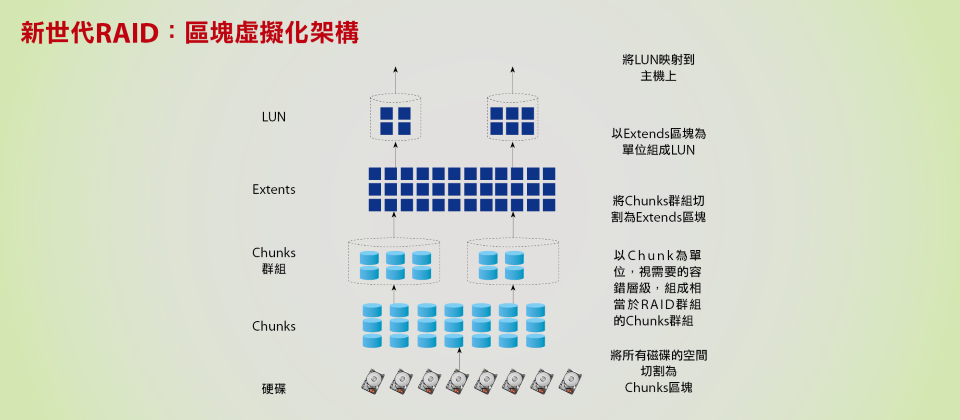
在新一代RAID架構下,從底層RAID磁碟群組到上層的LUN,全都是以虛擬化形式的區塊來建構,可讓LUN存取服務與RAID重建的負載都分散給系統中所有硬碟來承擔,無論LUN存取服務或RAID群組重建的效能,都可以有顯著的提升。(圖片來源/iThome)
隨著硬碟容量增加,RAID重建資料所需的時間也大幅延長,是當前企業儲存管理最讓人困擾的問題之一。
在過去硬碟容量只有幾十到幾百GB的時代,RAID重建是個十多分鐘以至數十分鐘就能完成的作業,尚不是需要特別擔憂的問題。不過隨著硬碟容量增長到數百GB以至TB等級,RAID重建時間也跟著暴漲到數小時甚至數十小時,已成為儲存管理的一大隱患。
傳統RAID架構的局限
傳統的RAID應用架構,是由磁碟機—RAID群組—LUN—主機的4層式階層結構所組成,選取一定數量的磁碟機組成RAID群組,指定其中一臺硬碟作為閒置的Hot Spare硬碟,然後依容量需求建立LUN,最後再將LUN映射給主機,成為主機上的儲存空間。
這樣的應用架構,存在著幾個局限:
首先,當RAID群組的硬碟損毀、導致需要重建時,只有該RAID群組的硬碟參與重建作業,且重建時的資料寫入負載集中在Hot Spare備援硬碟上,形成重建作業的瓶頸。
其次,LUN的資料存取,僅限於在一個RAID群組所屬的硬碟中進行,限制了主機端所能獲得的存取效能。
未竟全功的改良式RAID架構
為了解決傳統RAID架構的不足,後來出現了一種改進的RAID架構,可以橫跨多個RAID群組建立一個統一的儲存池,然後將儲存池的空間切為稱作Extent或Slice的均等小區塊,再以這種小區塊為單位組成LUN,並映射給主機使用。也就是說,LUN不是直接建立在RAID群組上,而是透過儲存池與小區塊的中介,再對應到底層RAID群組上,所以又可看作是一種「LUN的虛擬化」技術。
在這種改進的RAID架構下,可透過小區塊這一虛擬層的中介,將散布在多個RAID群組上的小區塊共同組成LUN,從而讓更多硬碟參與LUN的存取,讓主機端得到更好的存取效能,而且每一個LUN可以包含多個不同類型的RAID群組,也便於實施分層儲存應用。這種透過儲存池作為中介的虛擬化LUN技術,是當前企業級儲存陣列的RAID架構主流,EMC、HDS等大廠目前都是採用這種類型的架構。
但是在這種改良式RAID架構的底層,還是傳統的RAID群組,當個別RAID群組的硬碟損毀、需要重建資料時,依舊存在寫入負載集中在Hot Spare硬碟、以致重建時間過長問題。
新世代RAID 2.0架構登場
為了徹底解決RAID重建過長的問題,最終誕生了捨棄傳統RAID組成方式的新一代RAID架構。
傳統RAID是以個別硬碟為單位組成RAID群組,而HPE 3PAR、NetApp、華為等廠商推出的新一代的RAID架構,則改以更小的虛擬化區塊為單位來組成RAID,在建立RAID之前,先將所有硬碟的空間切為一個個區塊,稱作Chunk、Chunklet或Piece等,然後,以這種虛擬化區塊為單位、橫跨所有硬碟組成具備容錯能力,提供相當於RAID群組的區塊群組。最後再於區塊群組上,以更小的區塊(Extent)為單位,組成主機需要容量的LUN。
由於這種架構從底層RAID群組到上層的LUN,全都是以虛擬化的區塊來建構,也可稱作「區塊虛擬化」架構。
在這種新架構下,由於是以橫跨所有硬碟的小區塊為單位來組成RAID群組,Hot Spare空間也是由分散在所有硬碟上的空閒區塊來提供,所以當任一臺硬碟故障、需要重建時,RAID群組涉及的所有硬碟都會參與重建作業,且寫入負載也是分散在所有硬碟上,重建速度可比傳統RAID架構加快數十倍。
以HPE 3PAR的Fast RAID架構為開端,這類新一代RAID技術從7、8年前開始應用到磁碟陣列產品上,在兼顧傳統RAID的容錯能力與空間運用彈性之餘,又能解決資料重建速度問題。繼3PAR Fast RAID之後,接下來又陸續有NetApp的動態磁碟池(Dynamic Disk Pool)、華為的RAID 2.0+,以及IBM分散式RAID(Distributed RAID)等同類型的新型態RAID技術問世。
為了與過去的RAID架構區隔,我們可以把這些新一代RAID架構,稱作「RAID 2.0」。
-600-1-1000X2291.png)
分散式架構克服資料重建時間過長問題
打破RAID架構瓶頸
透過RAID將多臺硬碟組成磁碟陣列,目的在於結合多臺硬碟、獲得一個擁有更大容量、更高存取效能,且具備容錯能力的儲存空間,可抵抗磁碟失效的威脅,在硬碟失效時提供保護與回復資料的機制。
但是TB等級大容量硬碟的問世,卻讓過去行之有效的RAID資料回復機制,變得難以遂行。在RAID技術剛開始應用的時代,硬碟容量還是以MB計算,RAID重建時間還不是需要特別顧慮的問題,但當前硬碟容量已經成長100萬倍達到TB等級,連帶也讓RAID資料重建作業所需時間,延長到數十小時甚至上百小時,成為困擾儲存管理的首要難題之一。
為解決這個問題,近年來儲存廠商陸續推出新一代RAID架構,試圖在維持原有RAID架構的磁碟容錯與空間應用彈性之餘,有效縮短重建時間,也就是我們這裡所稱的「RAID 2.0」。
傳統RAID重建速度的瓶頸
-600-2.png)
RAID 5、RAID 6等普遍使用的傳統RAID架構,是透過設定Hot Spare硬碟,來替補RAID群組中失效的硬碟,讓系統透過資料回復機制(例如Parity資料的XOR運算等),在Hot Spare硬碟上重建失效硬碟的資料。
這種架構在雖然提供了回復資料的方法,卻也帶來了重建效能的瓶頸。RAID進行重建時,會從剩餘完好的硬碟上讀出資料、透過與Parity資料間的運算來算出失效硬碟上的資料,然後寫入到Hot Spare硬碟上,但傳統RAID架構的設計,會在重建作業過程中的資料讀取與寫入上,分別形成效能瓶頸:
● 在重建資料的讀取上,只有同一RAID群組的硬碟才會參與重建作業,因此造成了讀取速度的瓶頸。
● 在重建資料的寫入上,資料寫入負載集中在1或2臺Hot Spare硬碟上,造成重建寫入效率的瓶頸。
也就是說,RAID重建的速度,被卡在RAID群組規模與Hot Spare硬碟寫入效能這兩個瓶頸,隨著硬碟容量越大、包含資料越多,RAID重建時間也跟著線性增加。
過去10年來,機械式硬碟寫入速度雖然提升了50%,但容量卻成長10倍以上,使得過去只要幾十分鐘至幾小時就能完成的RAID重建作業,變成需耗費十多小時甚至數十小時以上的苦差事,在漫長的RAID重建期間內,磁碟陣列都是以降級狀態運行,效能只有正常狀態時的60~70%,而且容錯能力也會降低。
克服重建速度瓶頸的RAID 2.0
-600-3.png)
為了解決傳統RAID架構重建時間過長問題,RAID 2.0分別從改善傳統RAID重建作業的讀取方式,與寫入效能瓶頸下手。針對讀取瓶頸,採取的做法是「讓更多的硬碟參與重建作業」;針對寫入瓶頸,則採取「將寫入負載分散給所有硬碟共同承擔」的對策。
在RAID 2.0架構下資料被分散到磁碟陣列底層所有磁碟上,任一臺磁碟失效時,整個磁碟陣列都會受到影響,所以所有磁碟都會參與到重建作業中,從而消除重建時的讀取瓶頸。
另一方面,RAID 2.0也沒有傳統RAID的Hot Spare磁碟概念,不需指派個別硬碟來擔任Hot Spare硬碟,而是利用整個儲存池散布在所有磁碟的空閒區塊,來作為Hot Spare空間。所以進行重建作業時,也是由所有磁碟機一同承擔寫入負載,從而消除了寫入瓶頸。
而實現RAID 2.0架構的關鍵,在於分散式區塊虛擬化技術的應用。傳統RAID是以個別磁碟為單位組成RAID群組。RAID 2.0則是先透過一個虛擬層,將陣列中所有硬碟空間切割為一個個均等的虛擬化區塊,然後以虛擬化區塊為單位,跨所有硬碟建立相當於RAID群組的區塊群組,再於區塊群組上建立LUN。
所以,RAID 2.0每一個區塊群組、每一個LUN,都是由散布在所有硬碟上的虛擬化區塊所組成。如此一來,每一個LUN的空間是由陣列中所有硬碟共同提供,可改善效能;當任一硬碟失效時,也會牽涉到所有硬碟,由所有硬碟共同分攤重建作業負載,故提高了重建速度。
另一方面,虛擬化區塊架構還有減少RAID重建資料量的效益。傳統RAID是直接在RAID群組上建立LUN,重建時也是以整個LUN為單位。而RAID 2.0是以更小的區塊為單位組成RAID群組與LUN,系統可辨識哪些區塊已經被配置與使用,重建時只需重建那部分資料即可,因而可減少重建資料量,進而有助於縮短重建時間。
影響RAID重建時間的3大因素
為何RAID重建耗時
|
隨硬碟容量暴漲的RAID重建時間 隨著硬碟容量的提高,RAID重建時間也隨之線性增長,當使用4TB以上容量的硬碟組成RAID群組時,傳統RAID架構所需的重建時間將會提高到數十個小時。
|
-600-4.png)
影響RAID重建時間的因素主要有這3項:
組成磁碟群組的硬碟容量 硬碟容量越大,需要的重建時間也越長。
RAID群組包含的硬碟數量 RAID群組包含的硬碟數量,影響到系統從剩餘完好硬碟中讀取資料、寫入Hot Spare硬碟所需的時間,硬碟數量越多,重建時間也越長。
重建作業在儲存陣列系統中的優先等級 RAID重建期間,系統仍須承擔前端主機的I/O存取,如果分配給RAID重建作業的優先等級越高,重建速度也會越高,但是前端主機獲得的I/O效能也就越少。
其他次要影響因素還包括:
LUN實際切割的容量 RAID重建時只需重建LUN的資料,未被使用的RAID群組空間無需重建。如果一個RAID群組中只有部分空間被LUN使用,重建時間便會縮短。
RAID的型式 直接進行區塊對區塊複製的RAID 1與RAID 10,重建時間會比需要Parity計算的RAID 5與RAID 6更快。
考慮到每臺硬碟都有潛在的故障機率,RAID群組包含的硬碟數量越多,累積出現故障的機率也隨之增加,所以RAID群組的硬碟數量有一上限。
至於RAID重建作業在系統中的優先度,則關係到重建作業能分配到多少硬碟寫入效能。當前SATA硬碟寫入傳輸率大約可達150MB/s,理論上2小時就能向Hot Spare硬碟寫入1TB資料。但磁碟陣列在重建期間仍需繼續維持服務,會優先因應前端主機存取需求,在RAID重建期間的系統降級狀態下,通常仍能為前端主機提供60~70%效能,反過來說,重建作業只能使用30~40%效能。
相較於前面幾個因素,硬碟容量對重建速度的影響日漸增加,已成為首要的影響因素。
自從硬碟容量在2007年突破1TB大關後,8年間成長了10倍,目前已達到10TB。隨著硬碟容量提高,當RAID出現硬碟失效時,損失的資料量也成正比增加,需要重建的資料量與耗費時間也都跟著線性提高。以7200轉硬碟為基準,當RAID重建時,理論上為Hot Spare硬碟寫入1TB資料大約需要2個多小時,但由於系統還承載了其他負載,實際上可能會耗費3、4倍以上時間,耗用5~10小時是常見的情況,如果改用4TB硬碟,重建時間便會暴漲到20~40小時以上,換成8TB硬碟甚至會超過40~80小時。
這樣漫長的重建時間,顯然不是任何用戶所能接受,此時便是需要新一代RAID架構的時候。
熱門新聞

2025-12-12
2025-12-16

2025-12-17
2025-12-15
2025-12-15
2025-12-16