
由於大型語言模型ChatGPT今年走紅,再度掀起一波人工智慧應用風潮,除了促成許多軟體與服務層面的創新,各種可加速人工智慧處理的硬體運算技術,也受到各界熱烈關注。而身為全球半導體設計與製造重鎮的臺灣,不僅協助大型國際級廠商發展相關解決方案,也孕育出多家本土廠商加入這場世紀競局。
而在今年4月初,開放式工程聯盟(MLCommons)公布的MLPerf Inference效能測試提報結果中,就有一家臺灣AI加速晶片廠商名列其中,那就是2019年成立的創鑫智慧(Neuchips)。
事實上,在2020年10月MLCommons發表的Inference Datacenter v0.7效能測試結果,創鑫智慧就已提報,當時的系統組態採用FPGA晶片型態的RecAccel原形產品,鎖定開放原始碼的深度學習推薦模型(Deep Learning Recommendation Model,DLRM)AI應用情境,而在後續的Inference Datacenter v1.0、1.1、2.0,該公司提出的產品受測組態,改為FPGA加速板卡Terasic DE-10 Pro。
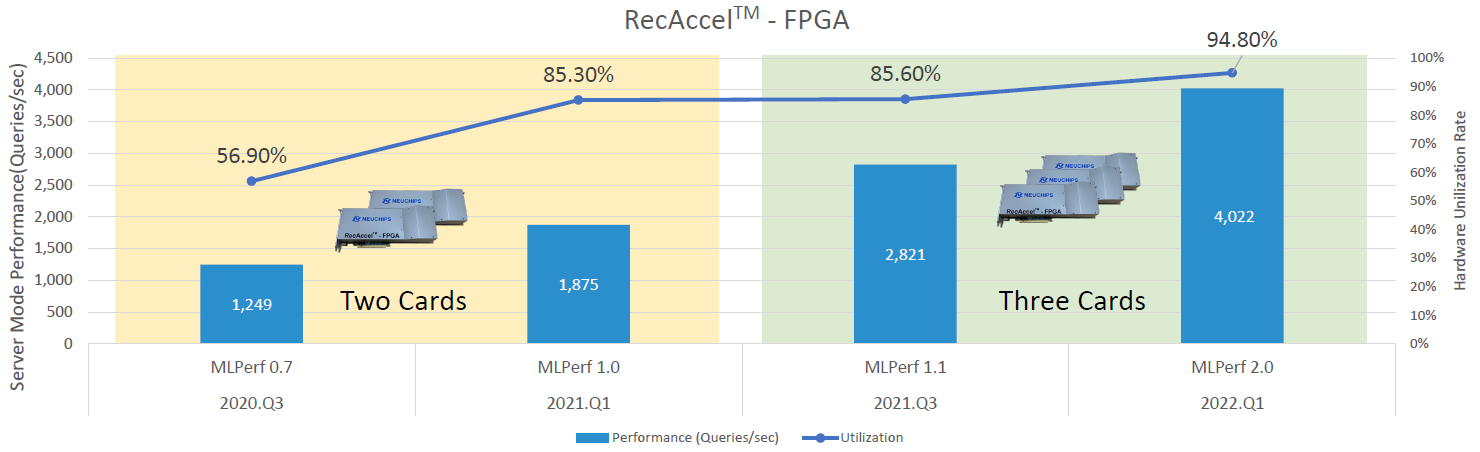
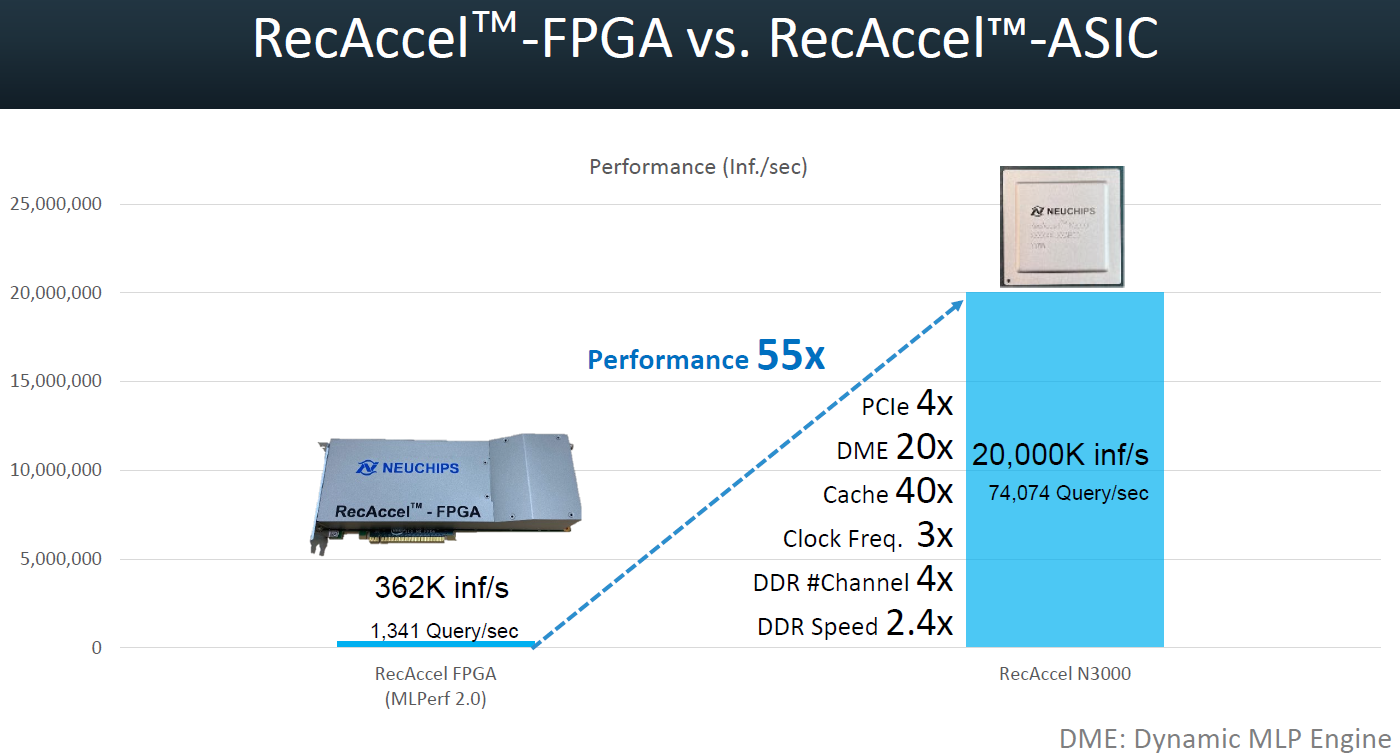
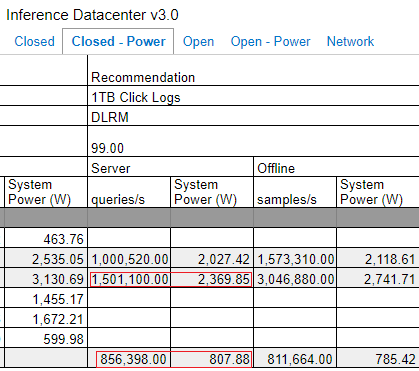
到了今年4月的公布Inference Datacenter v3.0,創鑫智慧提交兩份產品效能測試結果,均搭配他們去年5月發表的ASIC晶片加速卡RecAccel N3000,

其中一項測試是採用單張加速卡的配置,每秒可進行107,001次查詢,另一項測試則是擴充至8張加速卡,每秒可進行856,398次查詢,兩相對照之下,突顯這款產品可隨使用數量的增加,提供近100%幅度的運算效能線性擴展。

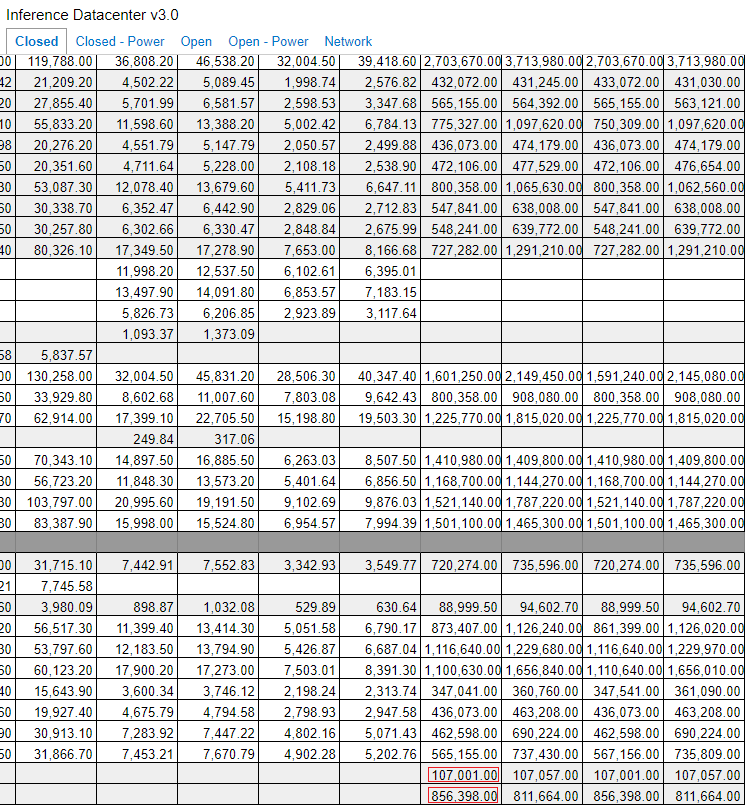
若基於上述這份效能測試結果,並以其中所列頂級資料中心GPU產品Nvidia H100的數據來比較,就DLRM推薦運算效能而言,搭配8張創鑫智慧RecAccel N3000的AMD二路(64核心CPU)伺服器,平均每1瓦電力每秒可查詢1060.05次(856,398次除以807.88瓦),搭配8張PCIe介面卡形式Nvidia H100的AMD二路(32核心CPU)伺服器,則是633.41次(1,501,100次除以2,369.85瓦),因此,N3000的每瓦推薦運算效能可達到H100的1.7倍。創鑫智慧表示,若改用另一款內建4顆RecAccel N3000晶片的加速卡來比較,可望將每瓦推薦運算效能領先幅度拉大,預估能達到H100的2.2倍。
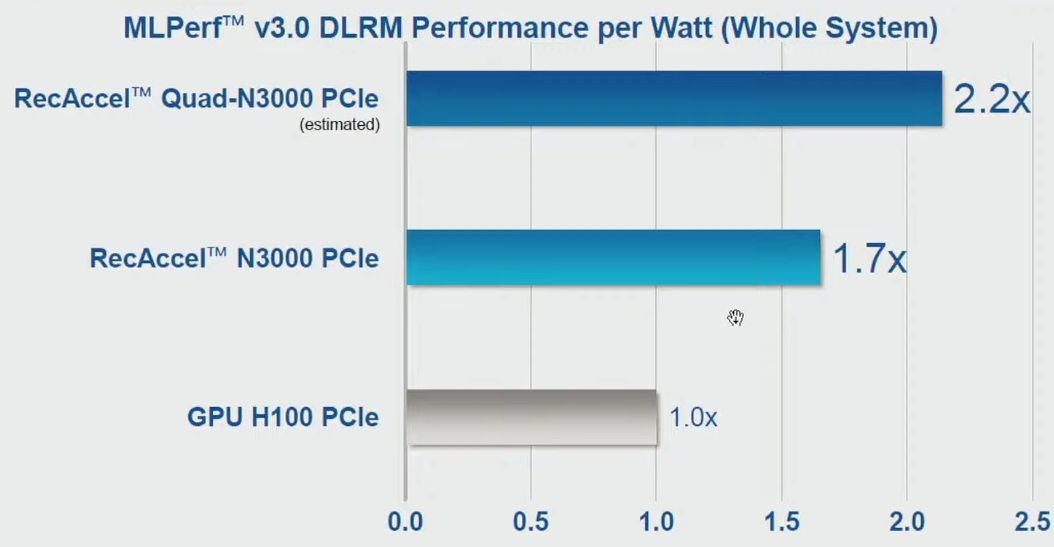
RecAccel N3000為何會有亮眼的能源使用效率?創鑫智慧僅簡單表示,因為這當中使用了INT8整數運算校準器,但僅僅只是這個原因嗎?
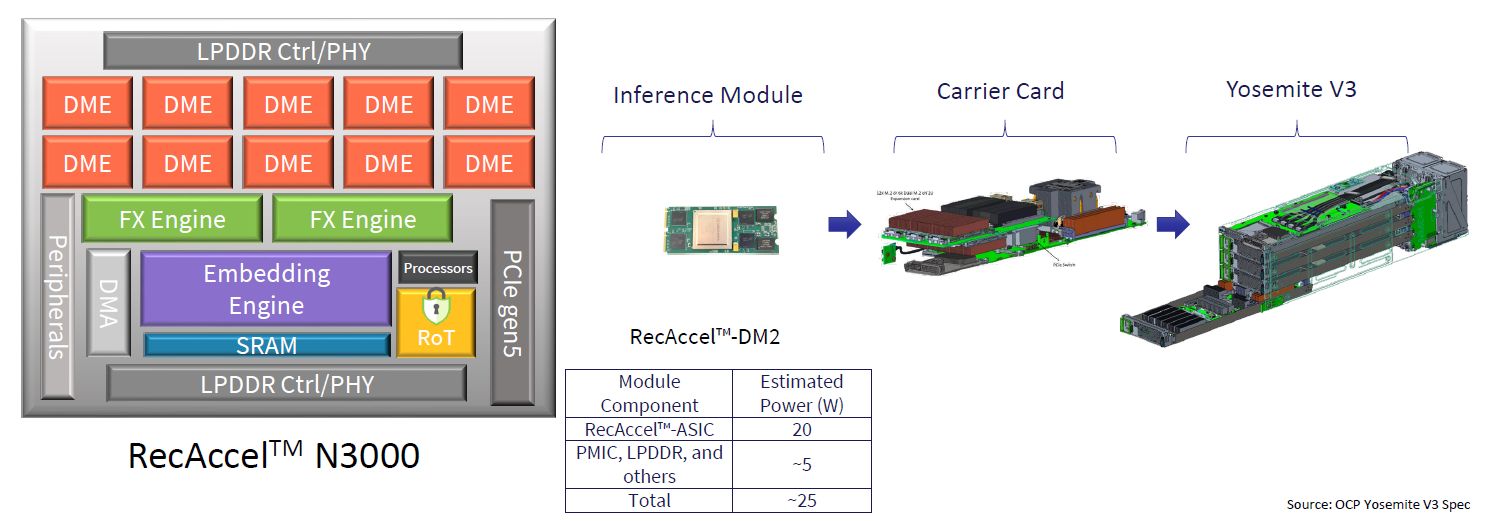
回顧去年該公司發表這款加速晶片的相關消息當中,我們可以看到還有其他技術優勢。例如,5月宣布推出RecAccel N3000時,他們提到這是一款首款專為深度學習推薦模型處理加速所設計的ASIC晶片,導入台積電7奈米製程,並將基於搭配這款晶片的雙M.2模組產品,針對遵循開放運算平臺(OCP)規格的伺服器,提供RecAccel N3000 Inference平臺,以及推出採用PCIe 5.0介面的加速卡,以安裝在資料中心的伺服器。
而在發展AI硬體架構與持續改良DLRM運算效能的同時,他們也在軟體層面進行共同設計,提供可廣泛應用的最佳化軟體堆疊架構,實現高精準的運算、硬體資源與能源利用率的目標。
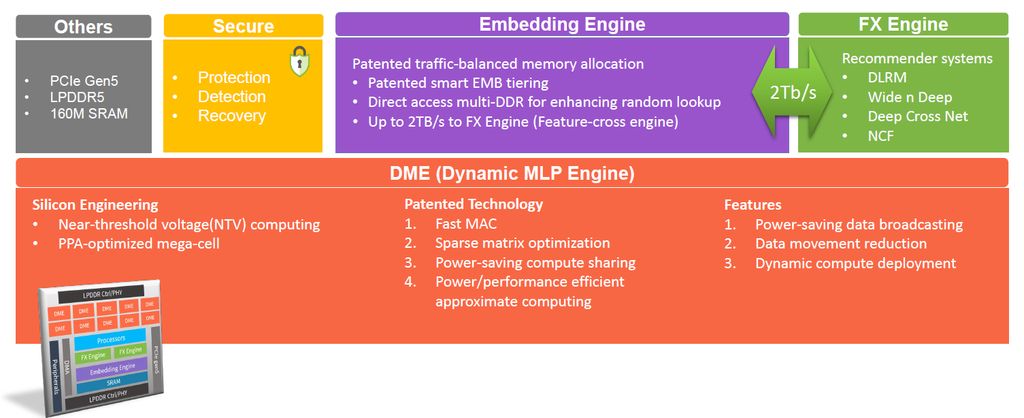
在AI推薦模型的部分,RecAccel N3000不僅支援DLRM,也支援WND(Wide & Deep)、DCN(Deep and Cross Network)、NCF(Neural Collaborative Filtering),而在安全性的部分,它也內建硬體信任根(RoT),可強化本身的保護。

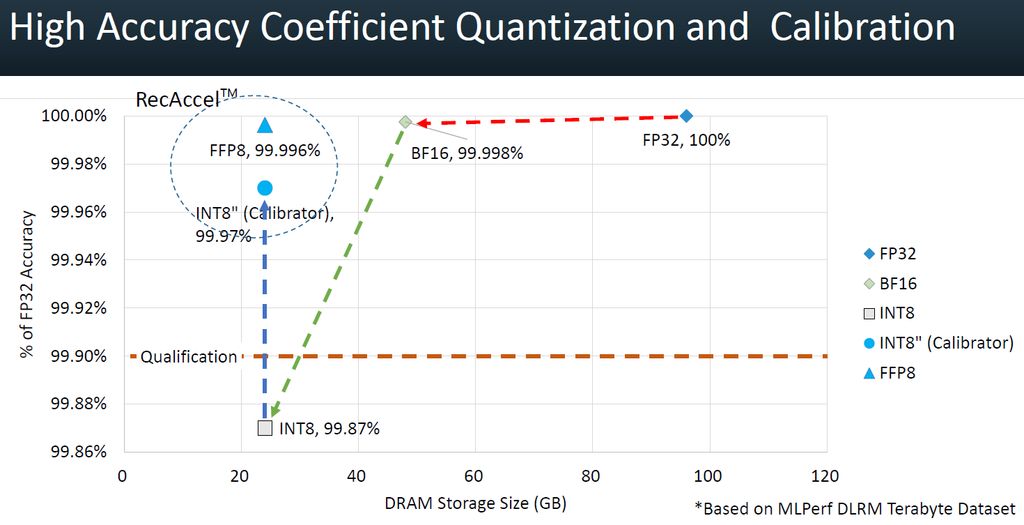
以精準度而言,他們發展出獨特的8位元協同運算技術,可結合量化處理、校準、硬體支援,將FP32運算的精度提升至99.95%;晶片內建專屬的多層感知器(Multilayer Perceptron,MLP)運算引擎,能在引擎層級提供立即可達到的能源使用效率,並且能在系統單晶片層級,實現每個推論處理只需1毫焦耳能量的理想。
在記憶體的存取方式上,創鑫智慧也開發出專屬的嵌入式引擎,具有新型快取設計與DRAM流量最佳化功能,能針對LPDDR5記憶體,減少50%存取需求,將記憶體頻寬利用率提升30%。
到了6月,創鑫智慧宣布RecAccel N3000進入投片生產階段,進一步揭露這款晶片組成與軟體堆疊架構。
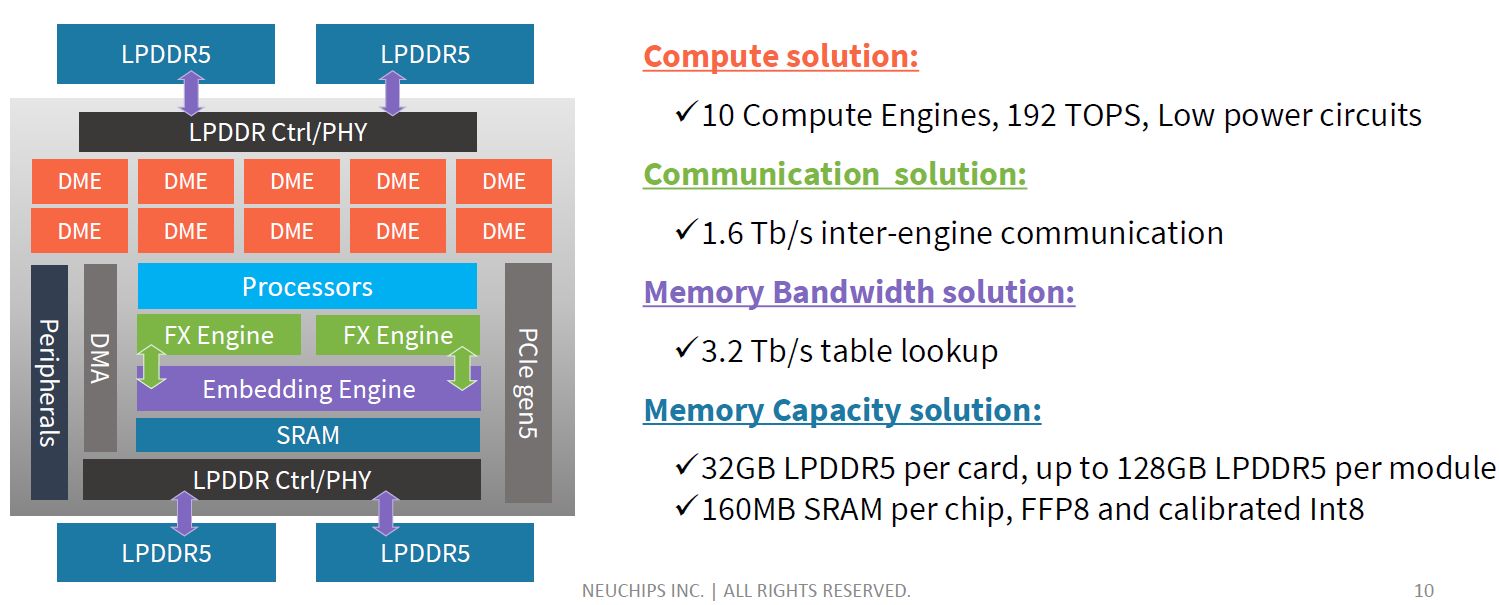
以運算引擎而言,當中分成嵌入型引擎、特徵互動(Feature-cross,FX)引擎,以及矩陣乘法引擎。其中的嵌入型引擎,針對目標是上述的記憶體存取效率,能大幅減少晶片以外的記憶體存取需求;特徵互動引擎則是指支援多種AI推薦模型的處理,可涵蓋DLRM、WND、DCN、NCF;至於矩陣乘法引擎,RecAccel N3000內建10個動態多層感知器運算引擎(Dynamic MLP Engine),而相關配置也是節省耗電量,以及有效率處理寬鬆矩陣運算的關鍵。
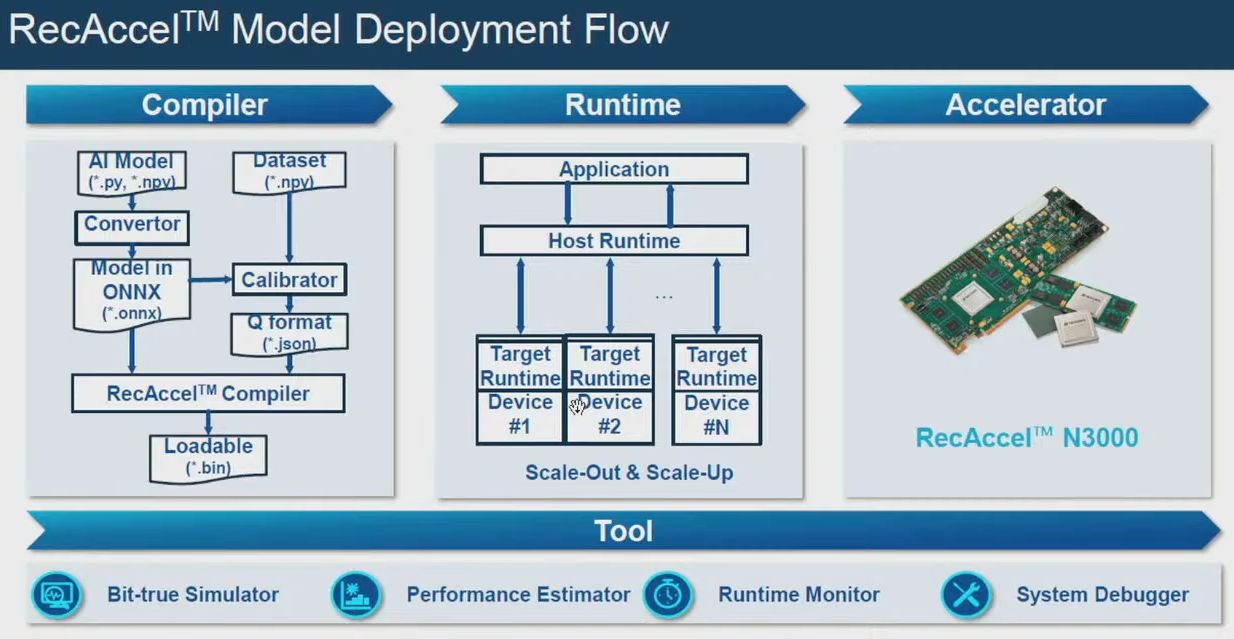
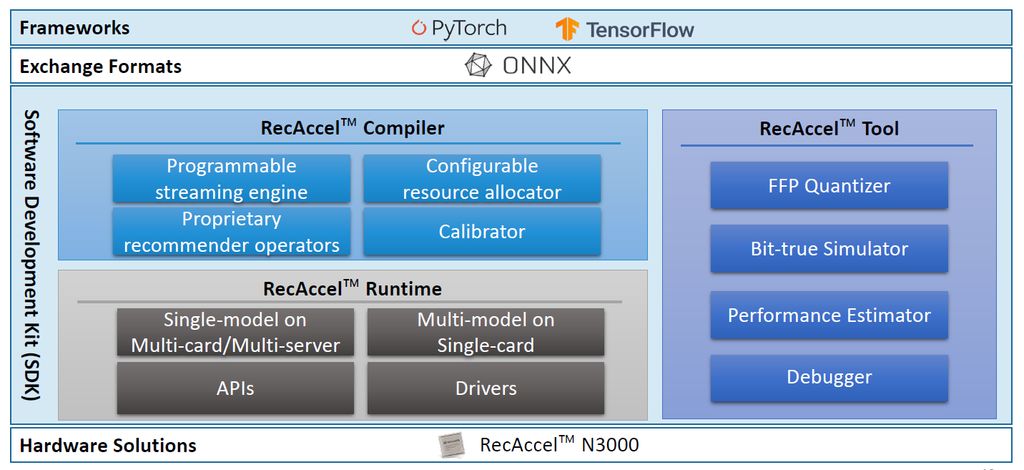
關於軟體堆疊方面,創鑫智慧揭露軟體開發套件將包含編譯器、執行時期元件,以及工具鏈,他們表示,當中將支援大模型分割、橫跨多顆晶片或加速運算卡的運算方式,能在每一顆晶片執行多個更小型的推論處理工作。
而在資料型別的使用上,創鑫智慧發展出新的8位元計數格式,稱為彈性浮點(Flexible Floating Point,FFP8),能促使晶片電路隨著AI模型的差異而調適,以此實現高精度的運算。除此之外,由於AI訓練皆採用32位元,所以大家能使用32位元來執行推論處理,若改用8位元來計算,耗電量可縮減至16分之1,但過往業界總是必須在精準度與運算效率之間做出抉擇,他們認為可透過FFP8,實踐更多的運算精準度,也能兼顧節約能源的需求。

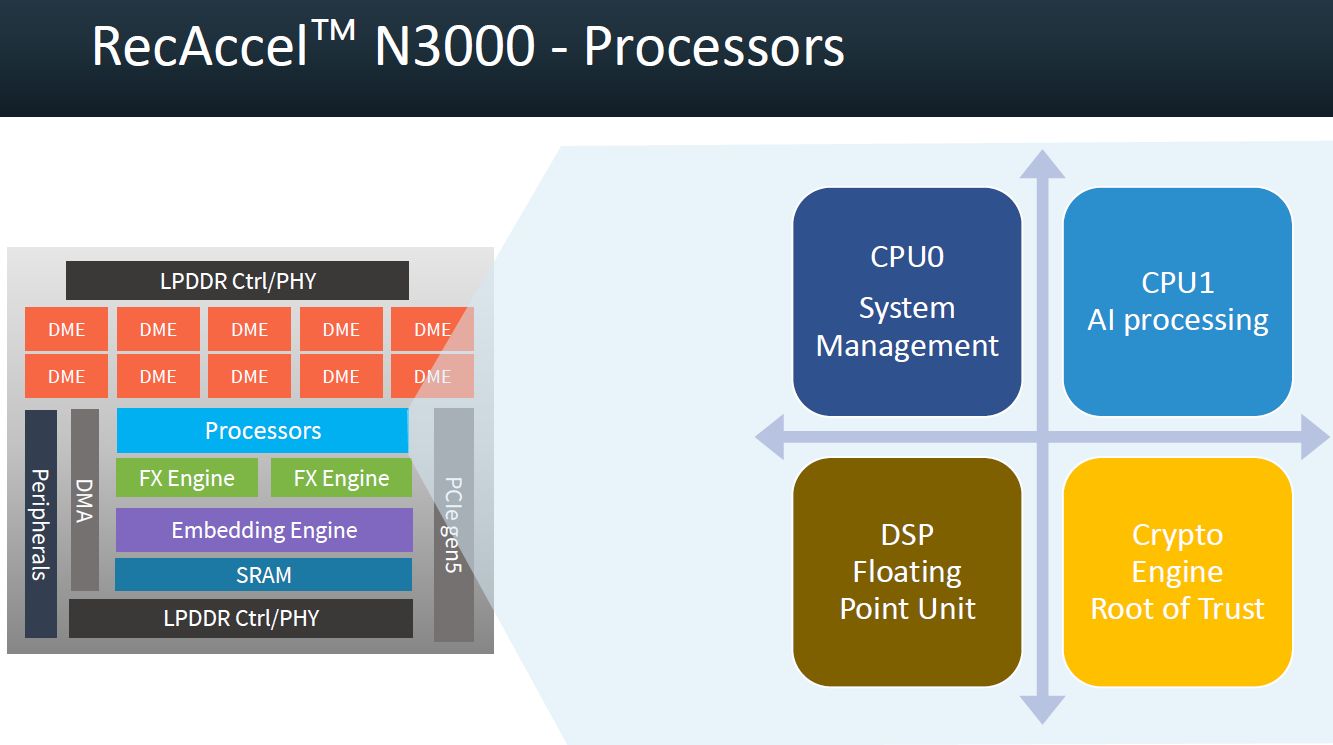
到了9月初,在電子設計自動化(EDA)公司Synopsys舉行的ARC Processor Summit 2022大會期間,創鑫智慧公開更多RecAccel N3000的規格與技術架構細節,例如,晶粒內建160 MB的SRAM記憶體,搭配的LPDDR5記憶體可配置為4個32 GB、內建線上錯誤修正處理(ECC),PCIe介面可支援3.0、4.0、5.0,最大可提供16個通道。
而且,他們也表明當中採用Synopsys旗下的多組矽晶片智慧財產,像是RecAccel N3000內建的處理器當中,結合了Synopsys的ARC EV72處理器,作為數位訊號處理器(DSP)與支援浮點運算處理;而在介面方面,這裡搭配Synopsys的進階高效能匯流排與周邊匯流排(AMBA)、LPDDR5、PCIe等智慧財產;在記憶體方面,搭配Synopsys Memory Compilers,可獲得進階電源管理功能;硬體安全方面,搭配Synopsys Hardware Secure Modules,而能具備硬體信任根,確保系統開機程式碼受到保護,也能執行裝置驗證。
產品資訊
創鑫智慧RecAccel N3000
●原廠:創鑫智慧
●建議售價:廠商未提供
●I/O介面:PCIe 5.0 x8
●外形:搭配單顆N3000的全高全長PCIe介面卡、搭配雙M.2款式、搭配4顆RecAccel N3000的PCIe介面卡
●運算晶片:台積電7奈米製程ASIC,內建10個DME運算引擎、2個FX引擎、1個嵌入式引擎
●運算引擎之間頻寬:1.6 Tb/s
●搭配記憶體:單顆N3000搭配32 GB LPDDR5-6400(每顆ASIC內建160 MB SRAM)
●運算效能:INT8為206 TOPS,FP16為35 TFLOPS
●耗電量:PCIe 5.0介面卡最大為70瓦
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞

2023-12-03

2024-04-24


2024-04-25

2024-04-26
2024-04-22

2024-04-22

2024-04-22