提升應用系統執行的可靠度,正是虛擬化平臺的看家本領,VMware在VMware Infrastructure 3時,就提供了名為High Availability(HA)的系統可靠度維持機制,在虛擬化環境下,一旦偵測到有ESXi主機故障的狀況,就會自動從其他臺主機上重新啟動原本在故障主機上的VM,並執行作業系統,如果純粹是VM中的作業系統出現停止運作的狀況,它也可以偵測到,此時VMware HA可設定這臺VM的作業系統自動重開機,以便恢復運作。
到了vSphere 4,VMware新增Fault Tolerance(FT),讓虛擬平臺上的系統可靠度維持,躍升到新的層次。FT會在其他ESXi主機上為本身所執行的主要VM,建立即時同步運作狀態的次要VM個體(live shadow instance),在面臨特定ESXi主機硬體故障時,容錯移轉機制會自動觸發,讓位於其他ESXi主機上的次要VM立即接手,達到VM不停機、零中斷的要求。
VMware提出上述兩種確保系統可靠度的作法,已行之有年,主要訴求都是希望在無需人為介入的情況下,自動因應ESXi主機與VM故障事件,然而,HA和VT所針對的事件都是整臺「主機」或個別「VM」層級的故障,當VM內執行的「應用程式」出現無法正常運作的狀況時,還是必須由系統管理者手動處理。而去年推出的vSphere 5.5,在這部份的保護上,提供新的作法,基於既有的HA功能,並結合vFabric Hyperic的技術,而擴充了高可用性功能,也就是App HA。
除了積極利用一些方法,讓VM、應用系統在其他臺ESXi主機「復活」起來,在系統可靠度的管理上,對於ESXi主機本身硬體的健康狀態,也需要有所預防,一般來說,伺服器硬體的運作最容易出問題的地方是磁碟,發生故障或損毀機率不小,但目前有許多方法能提升可靠度,例如建立RAID。比較麻煩的是記憶體,雖然市面上有些伺服器產品提供相關的記憶體備援機制,但對虛擬化平臺的執行來說,伺服器的記憶體能否正常運作至關重要,更不能出錯,在vSphere 5.5中也特別納入維持記憶體可靠度的功能Reliable Memory Technology(ReM)。
為了增加虛擬化平臺執行的可靠度,vSphere 5.5也改良一些與儲存應用相關的機制,增加彈性,讓它們更容易使用。例如:強化對Windows Server 2012叢集服務的支援,而且vSphere Replication、Storage vMotion和Storage DRS都能夠跨Datastore來搬移VM,同時在vSphere Replication的運用上,也能設定保留多個時間點的快照。
_01.png)
新推出App HA:系統可靠度保護擴及應用系統層級
在最新推出的vSphere 5.5版上,VMware除了原本的HA、FT之外,在企業版以上的授權版本又增加了新的App HA機制,企業可以利用它來保護VM裡面執行的應用系統,對於應用系統的運作狀態能夠加以監控,若出現服務異常,也可以自動重新啟動應用系統。
簡而言之,原本單靠vSphere HA要做到應用系統層級的監控與高可靠度機制,比較棘手,現在透過vSphere App HA來進行,作業方式可以比較簡化。
在vSphere 5.5版中,vSphere App HA可以保護幾種企業環境常見的應用系統:網站伺服器的部分,目前支援Apache HTTP Server和微軟IIS;入口網站平臺,目前支援微軟SharePoint Server;資料庫的部分,目前支援微軟SQL Server;Java應用程式伺服器的部分,支援Apache Tomcat和tc Server Runtime。
過去,企業如果想要確保ESXi主機與VM的運作可靠度,會透過vSphere HA來監控主機是否有I/O活動和Heartbeat,以及VM裡面安裝的VMware Tools是否有定期回報本身的Heartbeat來判斷。若偵測不到動靜,HA就會自動重新啟動VM。若想監控更多VM的狀態,可透過在VM上部署第三方應用軟體的代理程式,或利用vSphere Guest SDK開發出專屬代理程式,以搭配vSphere HA。但現在vSphere新版額外提供了App HA,用戶就不需借助外力,就能透過系統內建功能,來達到這樣的高可靠度需求。
就vSphere App HA的應用而言,它也能和原本vSphere HA的主機與應用程式監控機制合作,一旦偵測到主機故障、VM作業系統當機、應用系統停止運作等狀況,可以自動重新啟動主機、VM或應用系統,進一步延長應用系統正常上線運作的時間。
在這樣的合作方式下,vSphere App HA可設定成偵測到特定狀況發生時,由vSphere HA重啟應用程式服務。若應用程式還是無法重新啟動,此時,可以透過vSphere HA自動重啟VM。
_01(2).png)
支援多種常見應用系統的監控
新增高可靠性政策,要先選定應用程式服務的類型,目前提供的選項目有Apache HTTP Server和Tomcat,微軟的IIS、SQL Server、SharePoint Server和SpringSource tc Runtime。
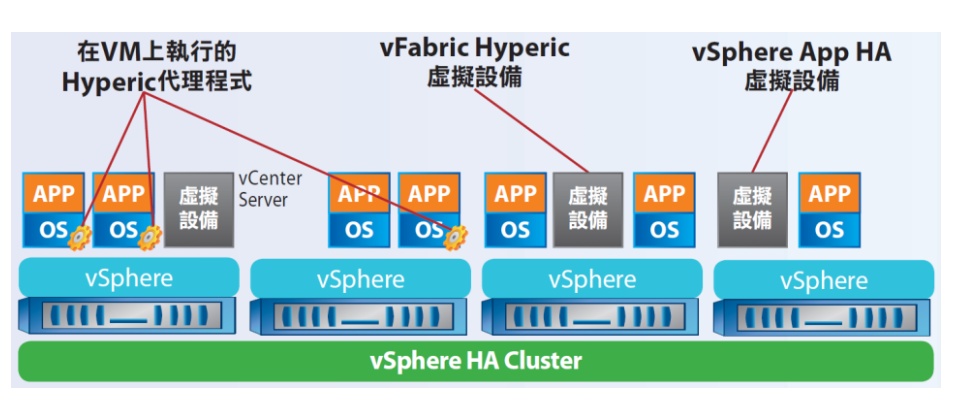
運作架構
若想要建置vSphere App HA的保護機制,以單臺vCenter Server的虛擬化環境而言,須部署vSphere App HA和vFabric Hyperic這兩臺虛擬設備,vSphere App HA負責儲存、管理vSphere App HA的政策,vFabric Hyperic則是負責監控應用系統,以及強制施行vSphere App HA的政策。
完成這些設備的部署後,管理者要將vFabric Hyperic代理程式安裝到執行應用系統的VM中,接著這些代理程式會與vFabric Hyperic虛擬設備溝通,以便vSphere App HA發揮保護作用。
可設定政策,自動執行App HA
想要設定vSphere App HA的政策,須透過vSphere Web Client來進行。在這些項目中,管理者可以定義vSphere App HA嘗試重啟應用系統服務的次數、等待服務啟動的時間,也能設定為:一旦服務啟動失敗次數太多時,就自動將VM重新開機。
此外,管理者還可以設定當服務中止時,就自動通知vCenter Server發出相關警告事件,同時寄出電子郵件給指定人員,提醒他們注意。
整體而言,vSphere App HA的出現,將VMware虛擬化平臺現有的高可靠度機制拉抬到新的層次,對既有用戶來說,也是相當具有吸引力的功能。趨勢科技研究開發部對此應用的需求,就是一個明顯的例子。
該公司有一座資料中心是專供產品研發人員測試用的使用環境,原本他們對於特定系統推新版時,就會進行測試公司產品是否與其相容的工作,因此也會用到vSphere 5.5,而vSphere App HA是他們覺得還不錯的功能之一,日後有可能會將它用在測試環境的準備上。
趨勢科技研究開發部的經理張豪文表示,vSphere App HA可以彌補過去vSphere HA不足的地方。同部門的資深工程師林威廷說,他們是將vSphere App HA用在一些常用的應用服務上,假設有10個專案都會連到特定的服務,他們會將這個服務以vApp 的方式提供出來,並讓它變成HA的架構,因此,這樣的服務不只是能夠多人使用,而且是會受到高可用度的保護。
_02(1).png)
可設定自動重新啟動應用程式或VM
管理者可對指定的應用程式服務,設定自動重新啟動的機制,當vSphere App HA監控機制偵測到服務中止或不穩定時,就會按照這邊的設定來重新啟動應用程式,若服務重啟之後,還是無法運作,還可以設定自動將該臺VM重新開機。
執行主機端HA時,可讓高負載VM不要過度聚集在特定主機
使用vSphere HA來保護系統的可靠度時,當遇到主機故障時,會觸動DRS(Distributed Resource Scheduler)來決定在哪一臺主機上啟動受主機故障影響到的VM,但以往在這種HA機制下,可能會出現一些負載較重的VM,過於集中在一臺主機上執行的狀況,而影響VM運作效能,而vSphere 5.5之後,也新增了相關功能,若適當運用,可設法避免這種狀況發生。
如何解決這種VM過於擁擠的現象?
需透過vSphere DRS來處理。管理者可以在該功能中,設定親和性規則(affinity rules),協助叢集內各主機上的VM能保持固定的執行位置,以VM之間的親和性規則為例,是指特定VM應該保持同在一臺ESXi主機執行,或分到不同臺ESXi主機上執行。
其中,能使特定VM保持在不同主機中運行的規則,稱為VM之間的疏離規則(antiaffinity rule),通常為了維持可靠度而用這樣的方式管理VM位置。若能支援這種原則的施行,實務上,可以解決VM過度集中在某些主機上所產生的效能衝擊。
在先前的vSphere環境中,vSphere HA並不特別偵測VM之間的疏離規則,所以當vSphere HA出現故障移轉的行動時,可能會有VM違反規則的狀況。根據不同環境而定,vSphere DRS若完全啟動,當它偵測到這樣的違規,會試圖執行vMotion,將其中1臺VM遷移到不同主機上,以滿足VM之間的疏離規則。但是,有了這樣的遷移機制,其實還不夠。在大多數環境下,上述的作業方式不會產生問題。然而,有些狀況可能會有嚴格的多租戶應用或需強制遵循的限制,因此VM需持續分離執行在不同主機上。另一種狀況是在對存取延遲極端敏感的應用系統,當這樣的VM在不同主機之間為此而作無謂的遷移時,可能又會對系統效能導致不利的效果
ESXi主機如果出現故障,為了能同時維持VM分散在不同主機上執行的需求,而且是不需透過vMotion遷移VM,vSphere HA勢必要尊重VM之間的疏離規則。
對此,VMware目前已經在vSphere 5.5當中,做到了這樣的改進,應用系統的可靠度維持,是由vSphere HA控制VM的執行位置,以做到復原,而不是利用遷移VM的方式。
用戶如果要啟用VM之間的疏離規則,實作上需手動變更設定,它是位在vSphere 5.5管理介面進階選項下,我們可以將das.respectVmVmAntiAffinityRules組態參數,設為True。
_03(1).png)
從BIOS 設定FRM 記憶體作業模式
想要在vSphere當中應用Reliable Memory技術,需升級到5.5版的企業版或企業進階版,而且伺服器硬體目前只有Dell 12代的PowerEdge部分機種,透過設備內建的FRM技術來支援,啟用該功能時,須先經由BIOS設定記憶體模式。
支援記憶體可靠度確保機制
在Windows環境中,許多人對於系統出現當機的藍色死亡畫面(Blue Screen of Death,BSOD),並不陌生,對VMware虛擬化平臺來說,也有類似的系統錯誤診斷機制,稱為紫色死亡畫面(Purple Screen of Death,PSOD),這種情況會發生,主要是因為ESX/ESXi的VMkernel執行上遭遇重大問題,導致VM的執行也跟著失效與中止。
事實上,這個VMkernel是ESXi Hypervisor最重要的部份,本身是一套為了執行VM所特製的作業系統,而且因為ESXi是直接執行在記憶體裡面,若過程中出現問題,連帶也使得Hypervisor和其中執行的VM跟著故障、當機。
對於ESXi主機記憶體突然發生錯誤的預防機制,以往vSphere並沒有著墨,然而到了5.5版,VMware開始支援維持記憶體可靠度的技術(Reliable Memory,ReM),它算是一種藉由處理器硬體所發展的特色,透過處理器的協助,它可向vSphere ESXi回報目前伺服器端記憶體當中,較為可靠的區域範圍,而有了這樣的資訊,能使整個虛擬化平臺運作得更為牢靠,增加不停機的時間,保護範圍包括VMkernel,以及ESXi的初始執行緒、hostd與Watchdog程序,同時,由於能參考較為可靠的記憶體區域,也有助於上述這些系統物件的執行位置最佳化。
目前要在vSphere環境中,使用這項預防記憶體錯誤的技術,需搭配特定廠牌、型號的硬體伺服器配備。各家廠商當中,Dell率先支援,他們在12代PowerEdge伺服器的部份機型裡面,已經開始提供了新的記憶體作業模式,並稱為記憶體錯誤回復(Fault Resilient Memory,FRM)。
該模式會建立一塊區域的記憶體,作為回復之用,若搭配支援FRM的作業系統時,可將重要的應用程式、服務與作業系統核心載入其中,以獲得最大的可靠性,而目前也唯有vSphere 5.5,透過新推出的維持記憶體可靠度技術來支援FRM。
_04.png)
FRM的運作架構
如何讓vSphere 5.5的ReM開始運作?VMware談的不多,我們只能從Dell目前對FRM應用的描繪,看到進一步的架構內容。
基本上,Dell FRM會在為Hypersior建立一個可迅速還原的記憶體區域,保護伺服器的運作,使整個系統在執行時,就算遭遇記憶體出錯的狀況也不會受影響,而vSphere 5.5會利用這塊區域,讓系統不會因此離線。
目前若要啟用FRM,有下列幾個條件。首先是伺服器,Dell 12代PowerEdge伺服器上總共有5款機型支援FRM,像是機架式伺服器R720、R720-XD、R620,刀鋒伺服器M620,以及直立式伺服器T620, BIOS需升級到2.0.19版以上,而且記憶體插入伺服器的插槽時,需支援記憶體鏡射模式;然後搭配的vSphere虛擬化平臺需為5.5版以後,而且是支援Reliable Memory Technology功能的特定版本(企業版、企業進階版)。
若上述條件都齊備了,接下來,管理者將Dell伺服器開機後,要先進入BIOS設定,在記憶體作業模式這一個項目下,選擇Dell Fault Resilient Mode,再存檔離開。之後安裝vSphere ESXi 5.5時,FRM保護區會自動建立起來、載入Hypervisor,系統預設會將VMkernel和其他重要的應用程式、服務,放在這個可靠的記憶體區域中執行,不需要在ESXi或vCenter上額外設定,就可以啟用。
若BIOS已經設定了FRM模式,但伺服器安裝的是vSphere 5.5以前或不支援ReM的作業系統,這個記憶體保護區還是會被建立起來,空間被會保留起來,而且該區域是處於動態使用狀態的,結果只是浪費記憶體。
若要查看ESXi是否啟動ReM,可以在主控臺的命令列介面,輸入「esxcli system settings kernel list | grep useReliableMem」,即可透過顯示相關的核心參數數值來判斷。另外,Dell伺服器本身內嵌的系統管理機制iDRAC,也會在系統事件記錄裡面收集FRM的相關事件。
此外,Dell本身針對虛擬化應用所推出的一些可靠度與備援機制,也可以搭配FRM,進一步提升VMware虛擬化平臺運作的穩定度與正常運作時間。
Dell這些額外的保護機制,包括位於伺服器機箱內部、裝有ESXi的雙SD卡,以及記憶體分頁回收(Memory Page Retire),尤其是記憶體分頁回收技術,有助於Hypersior定位、隔離記憶體中的特定區域,而這範圍的空間被標示的主要原因,是發生過很多次錯誤校正、但日後可能會出現無法校正錯誤的記憶體區域。
在支援vSphere 5.5的部分,Dell除了在既有伺服器產品內建FRM來強化虛擬化平臺的可靠度,Dell也推出2.0版OpenManage Integration for VMware vCenter來搭配新平臺的運用。這套軟體是將具有Lifecycle Controller 功能的iDRAC,以外掛的方式,整合在VMware vCenter的管理主控臺介面上,用戶可藉此快速管理Dell PowerEdge系列伺服器,同時可顯示啟用FRM技術的伺服器系統狀態。
熱門新聞

2025-12-31

2025-12-31

2025-12-31

2025-12-31

2025-12-31

2025-12-31