
現在大資料非用不可的分析工具是什麼?如果只知道Hadoop就落伍了,IBM首席科學家、負責IBM華生研究中心連結大資料部門,同時也在哥倫比亞大學開了最熱門的大資料分析課程的林清詠表示,大資料技術演變速度之快,每年都有很大的變化,去年還不需要提到Apache Spark架構,但是今年教大資料分析技術,不教Spark就落伍了。
Apache Spark是一個開源的叢集運算框架,採用了記憶體內運算技術(In-memory),由於可以用較少的節點數量,達到比Hadoop的MapReduce還高的執行效能,在這一、兩年內快速竄起,變得非常受歡迎。
而近幾年熱門的大資料技術Hadoop,林清詠卻認為熱潮已經不再,儘管Hadoop在過去10年不斷提供新的管理工具,也形成了龐大的生態系,但是Hadoop基本上已經是十幾年前的產品,考慮的是當時容量小且昂貴的記憶體和儲存空間等硬體條件,現在這些硬體技術前進,林清詠認為,10年前所考慮的軟體和架構不見得還適用。
以硬體面的進展來看,因為GPU的出現與發展,大幅提升運算效能,林清詠表示,GPU可用幾千個核心來進行分散式平行處理,運算概念和過去使用CPU的思維已經截然不同,因此,不需要使用Hadoop,也能執行大規模的運算。
9成5的企業其實不需要用Hadoop
根據他帶領的IBM研究團隊採用Hadoop的經驗,最後常常因為運算效能不夠好而浪費時間,此外,他也提到,由於Hadoop架構需要3倍的儲存空間,企業在採用時,常常會提出硬碟成本太高的問題。
他觀察,目前已經擁有大量資料的企業其實不多,但很多企業要導入大資料專案時,會盲目的採用如Hadoop這樣的大資料平臺,他說,有些企業會在多臺機器上部署Hadoop,但可能每一臺機器都只使用了百分之二十的效能,據他估計,有高達9成5的企業,在採用Hadoop之後發現,其實根本使用不到。
林清詠在紐約待了20年,目前負責IBM華生研究中心System G團隊,研究圖運算(Graph Computing)中的連結大資料(Linked Big Data)領域,也是三個大資料研究計畫的首席研究員,帶領由超過40位博士級研究員組成的全球IBM研究實驗室,以及包括20位以上來自10多所大學的教授及研究員的團隊。他也從2005年開始於哥倫比亞大學擔任兼職教授,去年開了一堂大資料分析課程,現在這門課修課學生超過三百人,是哥倫比亞大學內最受歡迎的一門課,修課學生跨資訊、統計及各個系所。
圖學是大資料未來的關鍵基礎,也是需要解決的問題
林清詠近日回臺灣在2015資料科學愛好者年會上分享了大資料的演進與發展,他認為,圖學(Graph)是大資料接下來發展的關鍵基礎,要解決多樣化資料的關聯性問題。
他說,大資料從2001年左右就出現,以前企業要採用大資料技術的首要問題是,資料要儲存在哪裡,怎麼快速分析資料,而這些問題不是單一硬體或技術可以解決的,當時大資料所需的各項技術都還沒到位,這就是為什麼大資料在十年前紅不起來的原因之一。
讓大資料現在變得熱門且必需的原因,林清詠認為,除了各項技術的進步之外,由於現在越來越多各式各樣的資料能夠被存取,每個人的行為和感測器的資料都可以被蒐集,而且儲存容量變得越來越便宜,儲存的資料不需要丟掉。此外,以前光是跟儲存廠商買資料庫服務,就得花費不少成本,且傳統資料庫有處理線上問題的限制,而現在多了開源軟體的選擇。
以技術面來看,大資料背後的技術包括大規模平行運算、大量資料儲存空間、資料分布、高速網路、高效能運算、運算工作及執行緒管理、資料採礦與分析等技術,林清詠說,當這些技術都已經越來越成熟之後,大資料才能演變成今天這樣。
而在技術成熟之下,林清詠認為,在大資料架構與擴充性問題上,必須要考慮的2大問題,分別為Scale out(水平擴充)和Scale up(垂直擴充),在Scale out需考慮的是,如何運用大量資源及平行運算來處理資料,通常會發生更高的資料延遲性,而Scale up的做法,則是要讓同一個機器的運算效果提升,發揮最大價值。
林清詠分別從大資料的3個特點(3V)來談發展現況,其中,在大量(Volume)及快速(Velocity)這2個特性,都已經有許多成熟的解決方案可採用,如要處理大量資時,可以採用Hadoop、Spark或是GPU來處理,要追求速度快的話,可以採用即時性的串流平臺,像是IBM的InfoSphere Streams或是Spark上的Stream平臺,強調可以處理即時性(Real-time)資料,第3個特點多樣性(Variety),則是接下來大資料技術需要被解決的問題。
他認為,要在多樣化的資料中找出相關性,關鍵在於資料之間的網絡關係(Network)和圖學(Graph),在學術界稱為網路科學,業界則稱作圖運算(Graph Computing),怎麼快速將資料串連,找出關聯性,他說,近幾年內幾乎所有大資料、資料採礦、資料庫的研討會,或是學術單位都一直在探討如何解決這個問題,IBM也一直在研究圖運算。
他提到,以前超級電腦用Top 500當作評價指標,以每秒可運算多少資料量來排名,從2010年左右開始,業界及學術界才逐漸理解,運算量不一定是最重要的,在有些應用案例中,更重要的指標是超級電腦每秒可以搜尋到、找到多少相關的資料,然後把這些資料儲存出來。因此,超級電腦社群才開始使用有Graph 500的評價指標。
林清詠指出,IBM團隊目前所處理到的Graph規模,超過8兆個節點(Node),串連出256兆個邊的關係(Edge),遠高於Facebook由超過10億個使用者的社交Graph,而Twitter在2012年的Graph規模大約是1億2千萬個節點,20億個邊。
在硬體方面,IBM發展了大約4年,其中一項SyNAPSE計畫,是要打造出大腦晶片(Brain chip),希望最終達到人腦1千億個神經元(Neuron),1百兆個突觸(Synapse)的規模,根據2年前的資料顯示,當時的Graph的複雜度規模已經達到貓的等級,要達到人腦的規模還要好幾年,不過,Graph規模達到之後,如何用來計算和處理也會是個問題。
免費釋出開源工具,加速臺灣資料分析技術發展
林清詠現場展示了IBM System G團隊進行的一項大腦網路分析計畫(Brain Network Analytics),分析老鼠在觀看不同圖像時,腦部神經網絡的反應情形,包括之間的關聯性,以及對什麼圖像會產生反應。早期的研究已經知道哪些神經元對應到哪些反應,而最終則是希望能知道同時刺激哪些神經元,可以產生不同記憶。
他也說,大部分的大資料都是互相連結的,稱作Linked Big Data,目前Linked Big Data研究的幾個重要方向,包括如何記憶、儲存相關的資料,此外,Linked Big Data可以使用其他的查詢語言(Query Language),不再是C語言。林清詠同時也宣布,System G團隊要將免費釋出開源的基礎圖學工具(systemg.research.ibm.com),提供各式各樣的圖學工具,讓大家可以在平臺上建置各式各樣的應用,希望能加速臺灣在資料分析領域的腳步,催生出更多應用。文⊙辜騰玉
2022/4/12 更正啟事:原提及人腦神經元數和突觸數有誤,正確應為人腦1千億個神經元和1百兆個突觸,內文已經更正。
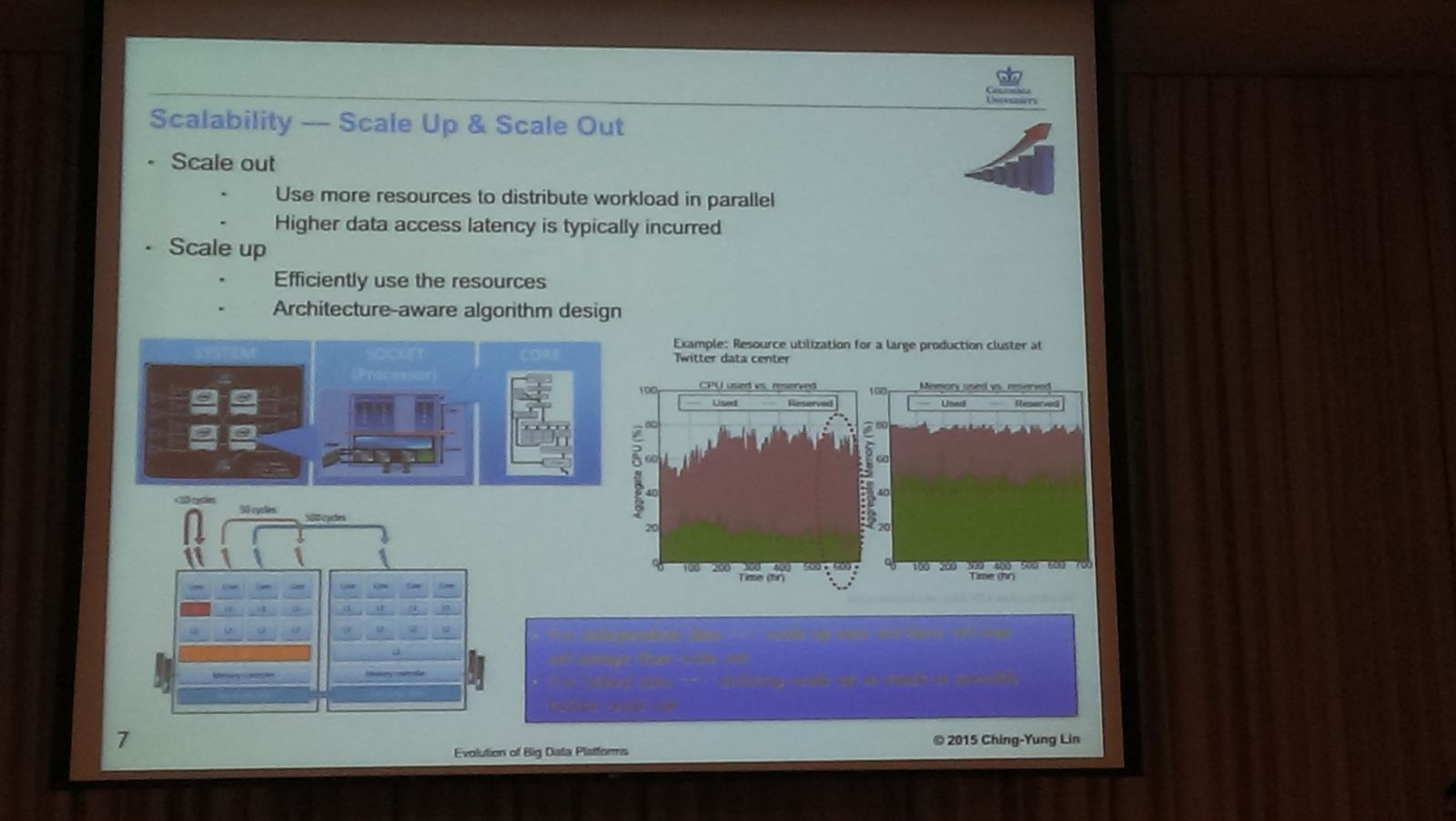
IBM首席科學家林清詠表示,在大資料架構與擴充性問題上,必須要考慮的2大問題,分別為Scale out(水平擴充)和Scaele up(垂直擴充),在Scale out需考慮的是,如何運用大量資源及平行運算來處理資料,通常會發生更高的資料延遲性,而Scale up的做法,則是要讓同一個機器的運算效果提升,發揮最大價值。
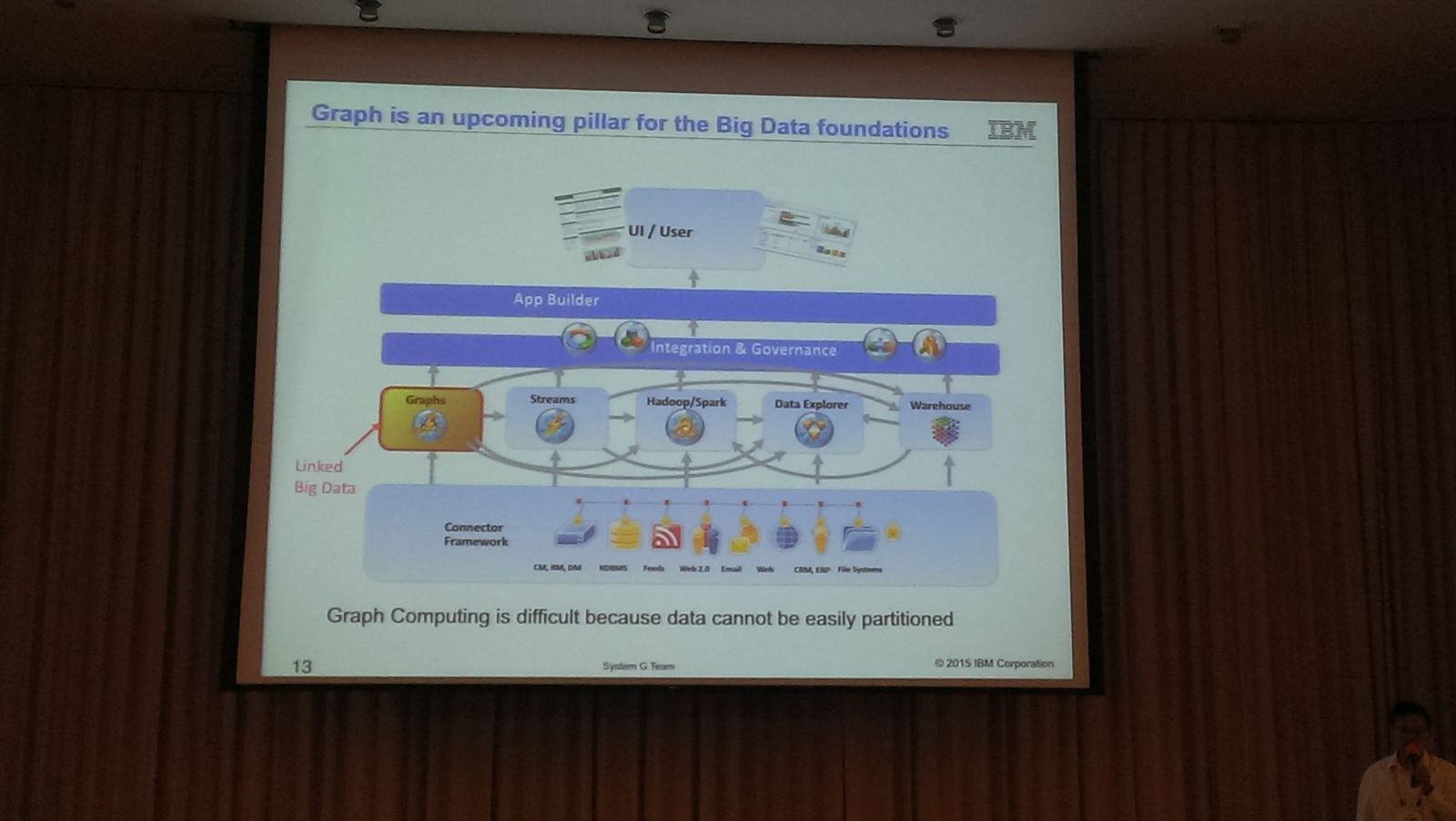
IBM首席科學家林清詠認為,要在多樣化的資料中找出相關性,關鍵在於是資料之間的網絡關係(Network)和圖學(Graph),在學術界稱為網路科學,業界則稱作圖運算(Graph Computing),而這也是接下來大資料要解決的問題,怎麼快速將資料串連,找出關聯性,他說,一直到2013年左右,幾乎所有大資料、資料採礦、資料庫的研討會,或是學術單位都一直在探討如何解決這個問題,IBM也一直在研究圖運算。
.jpg)
IBM首席科學家林清詠指出,IBM團隊目前所處理到的Graph規模,超過8兆個節點(Node),串連出256兆個邊的關係(Edge),遠高於Facebook由超過10億個使用者的社交Graph,而Twitter在2012年的Graph規模大約是1億2千萬個節點,20億個邊。

IBM首席科學家林清詠現場展示了IBM System G團隊進行的一項大腦網路分析計畫(Brain Network Analytics),分析老鼠在觀看不同圖像時,腦部神經網絡的反應情形,包括之間的關聯性,以及對什麼圖像會產生反應。早期的研究已經知道哪些神經元對應到哪些反應,而最終則是希望能知道同時刺激哪些神經元,可以產生不同記憶。

IBM首席科學家林清詠宣布,System G團隊要將基礎的圖學工具以Open Sourse的方式免費開放出來(systemg.research.ibm.com),提供各式各樣的工具,讓大家可以在平臺上建置各式各樣的應用,希望能加速臺灣在資料分析領域的腳步,催生出更多應用。
熱門新聞

2026-01-12

2026-01-12

2026-01-12
2026-01-12

2026-01-12
