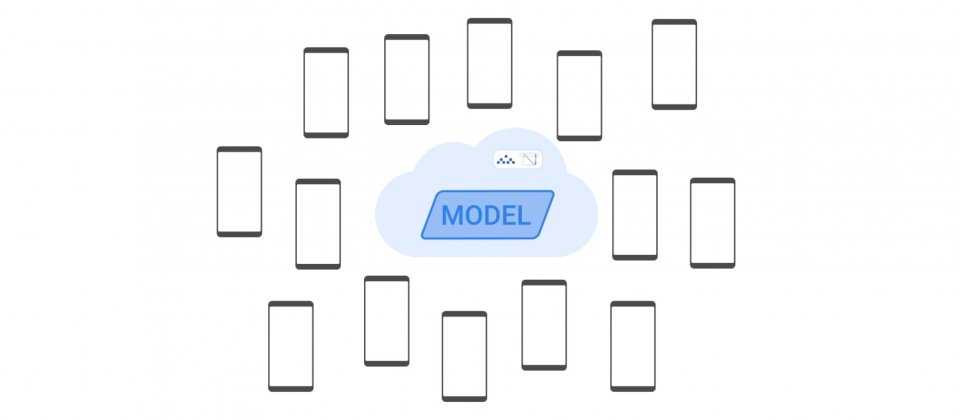
Google行動虛擬鍵盤應用程式Gboard中的所有下一個單字預測(Next Word Prediction,NWP)的神經網路語言模型,現在均採用聯合學習(Federated Learning,FL),並且提供差分隱私保證。另外,Google還進一步使用先進的演算法和增加參與模型訓練手機數量,來達到更高的隱私標準。
Google從2017年以來,開始研究以聯合學習私密訓練Gboard語言模型,並在2022年正式應用差分隱私。聯合學習允許行動裝置在不共用資料的情況下協作訓練模型,而差分隱私則是提供資料匿名的可量化衡量標準。
目前超過30多個Gboard裝置上語言模型,已經在超過7種語言和15個以上的國家中推出,並且具有差分隱私保證,Google提到,這是目前已知最大的用戶等級差分隱私部署,並且針對直接使用用戶資料訓練的模型提供差分隱私保證。
Google向Gboard用戶提供資料使用相關資料,包括資料的使用目的、處理方式,並讓用戶可以簡單配置學習模型的資料使用。聯合學習只會聚合有助於特定模型改進的更新,來最小化資料使用量,而且Google所採用的安全聚合(SecAgg)加密方法,進一步保證聯合學習只能存取臨時更新的聚合結果,確保只有合併後的更新資訊會被用於改進模型,且不會使用任意個別用戶的資料。伺服器也應用差分隱私,來防止模型記住單一使用者訓練資料中的獨特資料。
Gboard中所有打字預測模型都具差分隱私保證,代表著在使用用戶打字資料改善預測準確度的同時,也就能確保個人資料的匿名和安全。在聯合學習中,Gooogle透過使用多語言C4資料集預訓練模型,並在公共資料集中進行實驗模擬,找出一個最佳的雜訊比,使模型能夠有效運作卻又不會洩漏個人資料。在限制用戶於一定時間內只能貢獻模型一次,將有助於提升隱私,並且限制每次更新對模型的影響程度。
而在運用差分隱私保護用戶打字隱私的同時,Google也持續改進差分隱私,將模型隱私保護強度提高至新的層級,特別是在巴西的葡萄牙語和拉丁美洲的西班牙語模型,官方提到,透過使用先進的MF-DP-FTRL演算法,並讓每輪參與伺服器模型更新的裝置增加至12,000個,就能達到更強的隱私保證。
Google對聯合學習與差分隱私的研究,證實透過客戶端的參與度和系統演算法設計,實作差分隱私是可行的方法。當人群規模龐大且匯集大量裝置的貢獻時,隱私和效果都可達到較高的水準。而隱私審查結果證明了,即便是差分隱私最壞的情況發生,實際上其所提供的保護仍高於預期。
目前Google正在研究機器學習相關的所有隱私方法,並且擴展差分隱私技術,使其可用於分散式系統,同時Google也在增加系統的可稽核性和可驗證性。
熱門新聞

2023-12-03

2024-04-24


2024-04-25

2024-04-26
")
2024-04-26
2024-04-25
2024-04-22