高盛是全球超大型投資集團之一, 他們有一套用來分析龐大證券交易風險和估價的關鍵平臺SecDB,來協助高盛集團旗下的交易員,評估什麼時候買哪一些股票的風險有多大。這個平臺,正是讓高盛證券交易員們一年獲利數十億美元的關鍵系統。
SecDB平臺已經用了30年,每天要執行1.6億個任務,目前負責維護這套系統的開發人力超過了3千人。這套系統還設計了自己專屬的程式語言Slang,多年來累計超過了2億行Slang的程式碼。目前全球有1萬3千名使用者,不只是交易員,還有許多分析人員。這套系統一但出現問題,甚至發生短暫當機,不只會影響了高盛的證券交易的風險評估,甚至連高盛銀行的業務都會有影響。這是高盛全集團的關鍵系統之一。
SecDB串接全球上萬資料庫,可支援25億個連線數
為了支援各種不同的使用情境,SecDB平臺也發展出了許多原生應用,串接了1萬多個分散在全球的物件資料庫,所能支援的連線數超過25億個連線,每秒接收的流入資料頻寬多達164TB, 對外流出的資料頻寬,更是達到每秒8PB的海量資料。可以說,SecDB和伴隨的相關應用,組合成了一個龐大的分析生態圈,而SecDB平臺就是其中的關鍵核心。
如何強化一個發展了30年的龐大老舊系統,是非常困難的挑戰,尤其近幾年,這套系統韌性面對的局勢,每一年都在改變,可能來自各式各樣的新興網路威脅,新興金融使用情境,新興技術的汰換和進化,這些變化再再考驗了SecDB系統的韌性。為了更徹底掌握SecDB系統的運作情況,3年前,高盛開始打造這套關鍵系統的可觀察性能力。
原本的SecDB平臺為了提供高速分析能力,採用了記憶體式鍵值(Key-value)資料庫,並採取了叢集架構的設計,由一個保持最終一致性的複寫叢集群組,高盛稱其為Ring AP,把資料寫入到這個叢集群組中的任何一個資料庫節點成員,來建立高度分散式的效能。
在這個群組中的資料庫節點,例如有紐約SecDB資料庫,倫敦SecDB,香港SecDB資料庫,彼此之間還會透過一支同步程式SecSync,可以自動更新和移除彼此不一致的地方來確保,資料庫的最終一致性。
舊有時間序列資料分析工具,不擅長即時維運分析
數十年來,SecDB資料庫團隊也打造過好幾種監控機制,最近主要使用的監控矩陣SecDB Metrics,是以時間序列資料庫來搜集各種事件後,進行例行檢查,也能用來 來診斷各式各樣的已知問題。例如資料庫組態可用記憶體限制、連線限制數的問題等。而資料庫管理人員也常用一款時間序列資料分析工具PlotTool,運用各種數值分析,來了解這些時間序列資料的維運效能 。
例如高盛資料庫管理人員曾用PlotTool來繪製出資料庫所用記憶體的變化趨勢,原有標準配置的記憶體配置上限是 60GB,但從分析趨勢可以看到資料庫的記憶體用量需求越來越大,就可以在特定時間後,將上限值拉高到70GB。用這樣的繪圖工具來看記憶體用量的長期變化趨勢,可 以更視覺化地觀察維運作法上需要調整之處。
高盛用了多年的時間序列資料庫和PlotTool都是好用的維運工具,雖然有用,但是還是有所不足,因為這些適合用來觀察長期趨勢,而不是即時性的系統監控機制。尤其,就有監測矩陣所用的時間序列資料庫,適合用來儲存即時的金融資料和分析這些金融資料,但是,不擅長用於即時維運系統訊號的處理。
3年前,高盛開始另外用批次處理程式,來產生各種分析報表,若有異常或需要注意的訊號,也只能透過電子郵件通知相關人員來處理,時效性比較不足。
可是,這幾年來,SecDB平臺串接的資料庫越來越多,產生的電子郵件通知數量和各種維護問題越來越多,高盛發現,他們需要一個平臺,可以立即注意到關鍵事件出現。
採用開源事件監控平臺Prometheus打造可觀察性架構
高盛SecDB平臺團隊和SRE團隊討論後,決定使用開源事件監控平臺Prometheus,用這個Prometheus 自己的數據查詢語言PromQL來開發監控機制,並改用Prometheus的通報管理功能Alertmanager來發送異常通報。
為了避免影響到原有的資料庫,高盛打造了一隻探測程式,並在SecDB所在的每一臺主機上,會放了一個Daemon程序,可以和外部的探測程式溝通,將搜集這臺主機上的運作狀態Log數據,這隻探測程式還會將各種事件和Log資料,整理成Prometheus格式的資料,再匯入到SRE團隊管理的Prometheus主機上,最後,資料庫團隊可以在Prometheus所有SecDB平臺的狀態儀表板。
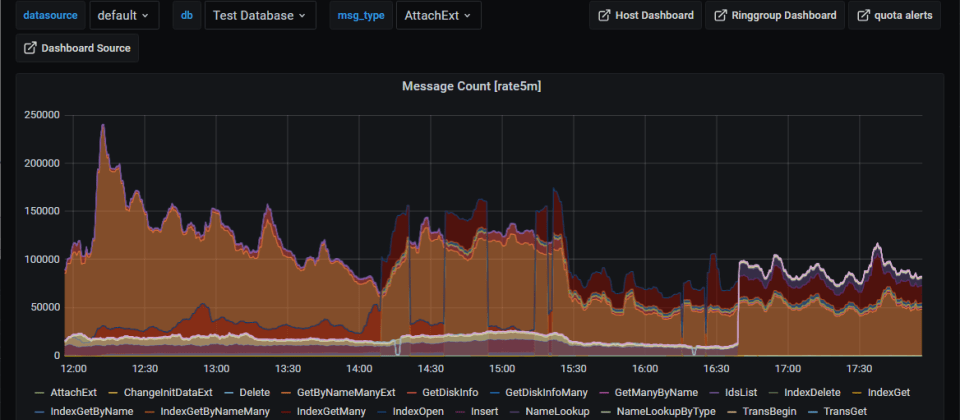
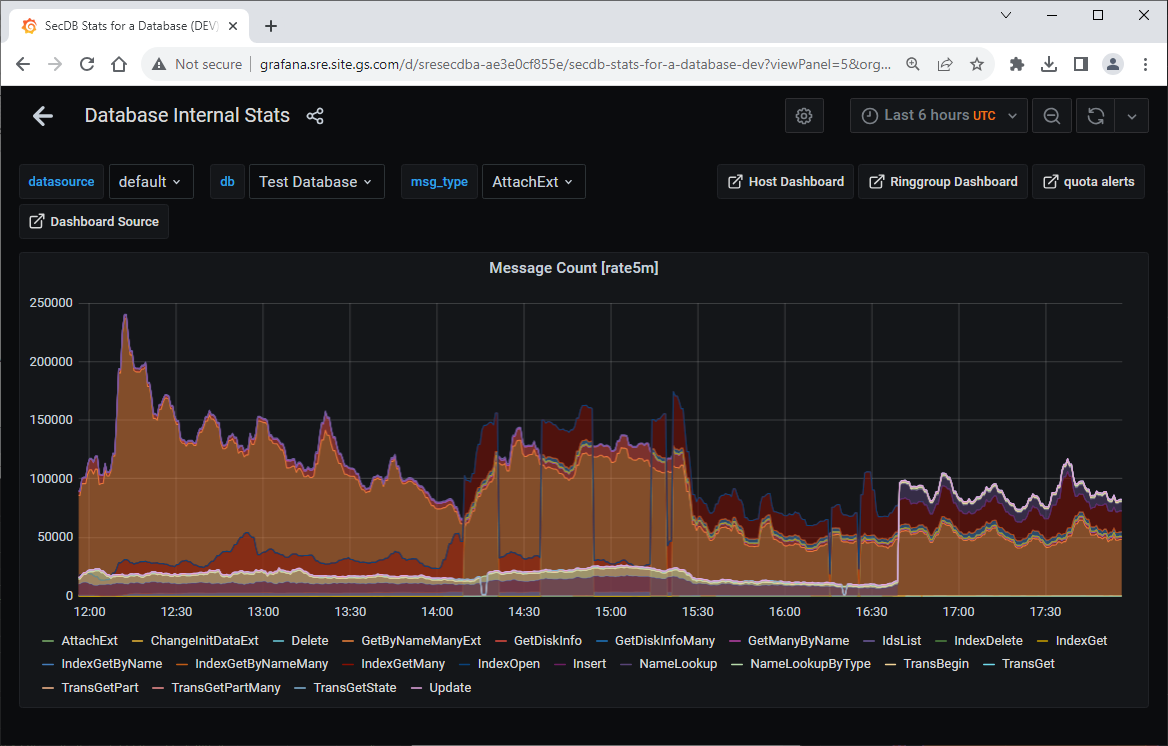
在這個SecDB儀表板上,可以看過過去6個小時內,每一分鐘,每一臺SecDC主機的數據變化,例如每一分鐘使用了多少記憶體,資料庫讀取的利用率有多高等等。 透過這些搜集主機狀態的觀察手段,可以建立整個Ring AP叢集群組中,每一臺主機、每一個資料庫的監測儀表板。
高盛使用了PromQL規則來定義各種事件的觸發條件,來判斷不同事件需要驅動哪一種等級的維運高風險通報。多數不緊急的事件只需要發出後續追蹤處理的通知,但是對於關鍵事件,則會觸發一個特別的通報機制稱為 PagerDuty,直接發布通報給待命工程師。
盡可能避免影響原有平臺,採用指標伺服器從旁搜集遙測資料
高盛SecDB團隊打造可觀察性功能時,有一個大前提是,盡可能避免影響到SecDB平臺的系統來搜集需要的SecDB平臺Log資料。所以,他們後來的作法,不是在SecDB平臺系統中增加監測機制,而是改在每一個SecDB所部署的主機上,用Daemon程序來安裝一個指標伺服器(Metrics Server),用來可以提供這臺主機的即時資料庫遙測,一但主機發生任何狀況發生,都可以立即看到。這個指標伺服器,跟主機上的SecDB平臺資料庫,共用同樣的記憶體,位在同樣的環境中,也就可以用來代表SecDB所在主機的狀態。這個即時監測手段,讓高盛的資料庫團隊能夠用新的角度來思考他們的基礎架構。
不過,這個指標伺服器,因為高併發運作和鎖定問題,無法使用現成的Prometheus函式庫,後來,高盛乾脆自己開發了新版的指標伺服器元件。新版指標伺服器不只可以搜集主機數據,還可以搜集到資料庫內部的遙測數據,包括資料庫透過內部工作流程進行交易的狀態資訊,這就大大提供了過去看不到的透明度。多達二、三十種資料庫的運作行為,像是新增一筆紀錄,刪除紀錄,開始交易,交易資訊取得等行為,都可以即時看到狀態資訊的變化。
新版指標伺服器不只可以搜集到SecDB所在主機的遙測數據,連資料庫內部運作行為的數據也能搜集
因為這套DecDB在全球各地都有節點,如紐約SecDB資料庫節點、倫敦節點、香港節點等,後來,高盛將這套監控架構發展成了全球多區域的架構,每個區域各有一套自己的Prometheus,遙測資料先集中到各地SecDB的Prometheus後,再把資料匯入到SRE團隊的Prometheus上來提供整合性儀表板。高盛SRE團隊也會提供了SecDB的SLO達成情況,方便資料庫團隊追蹤每一天的維運狀態。
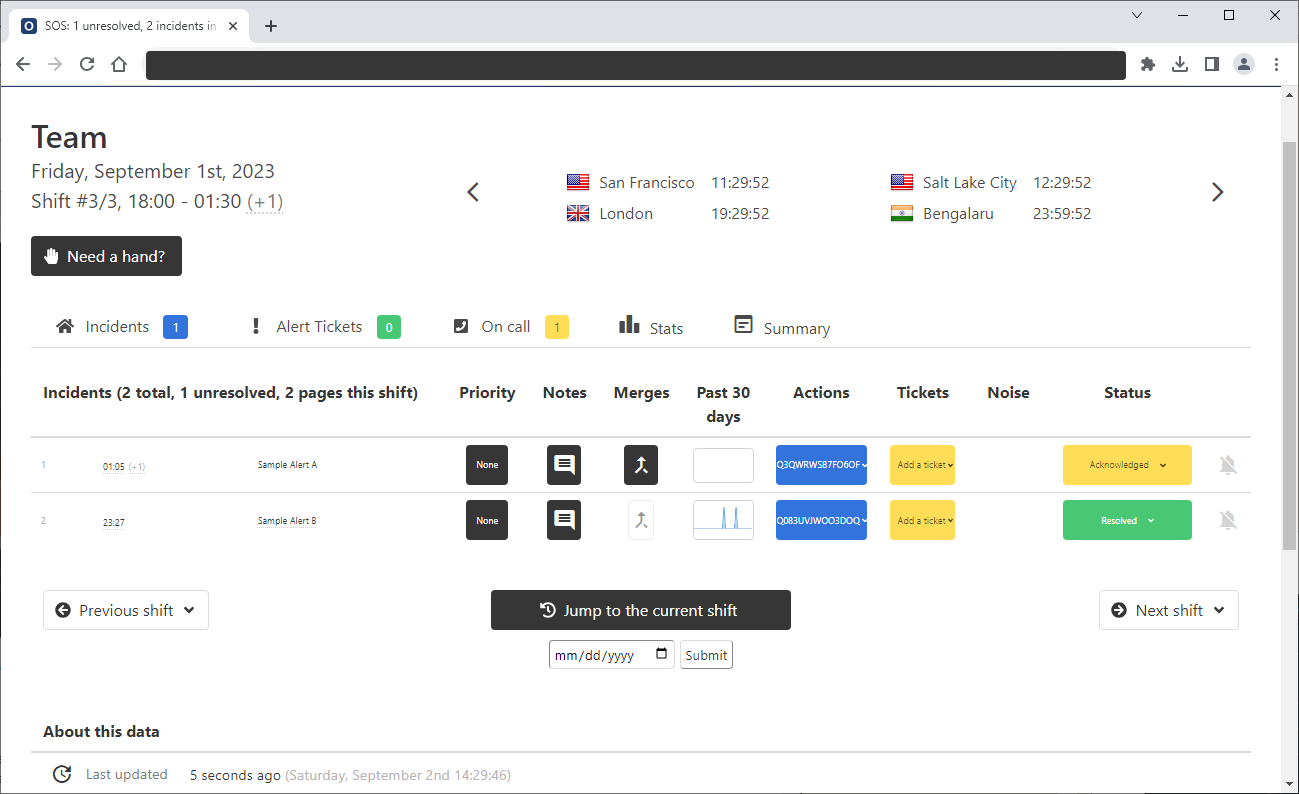
因為SecDB是全球運作,而且是24小時都不能停,而且得支援全球不同時區的需求。每個區域會有6個待命工程師,每周輪流接手,來和全球的待命團隊(SRE)成員合作。為了各區域值班待命工程師的工作銜接,也讓他們有能力處理更多示警通報的管理,高盛還打造了一個SOS系統,紀錄每一起事件的處理情況,方便不同區域之間的工作交接。
高盛打造了一個SOS系統,來紀錄每一起事件的處理清況,方便全球不同時區團隊的工作交接。
2023年,高盛完成了SecDB平臺的可觀察性架構之後,開始將這個機制延伸到其他SecDB平臺的各種相關應用,預計在2024年涵蓋到所有相關應用,都要納入同一套可觀察性架構下。
熱門新聞

2023-12-03

2024-04-24


2024-04-25

2024-04-26
2024-04-22

2024-04-22

2024-04-22