
Google新論文介紹影片生成模型Lumiere,Lumiere是一種文字轉影片擴散模型,該模型的主要目的,是創建真實、多樣且動作連貫的影片。該模型使用一種稱為時空U-Net(Space-Time U-Net,STUNet)基礎架構,官方提到,這種技術可以一次生成完整的影片長度,而不需要經過多次處理。
近年圖像生成模型有著巨大的進步,能夠根據複雜的文字提示,生成高解析度且逼真的圖像,不過,研究人員要將文字轉圖像技術應用到文字轉影片領域面臨挑戰,主要原因在於影片中的動作複雜性。
當前文字轉影片模型仍然無法生成長時間,有著高品質視覺效果且動作逼真的影片,研究人員解釋,這些模型通常採用分階段設計,會先生成幾個關鍵畫面,接著用時間超解析度(Temporal Super-Resolution,TSR)模型,填充關鍵畫面之間的畫面。該方法雖然在記憶體效率上表現良好,但是在生成連貫動作上有其限制。
Google的新模型Lumiere則採用不同的方法,使用STUNet架構一次性生成完整時間長度的影片,該架構能夠在空間和時間上同時降採樣(Downsample)訊號,在更緊湊的時空表示中進行大部分運算,這使得Lumiere能夠生成更長時間、動作更加連貫的影片。Lumiere一次可以生成80影格,以每秒16影格來算,可產生長達5秒的影片,研究人員提到,5秒的長度超過大多數媒體作品中平均鏡頭時長。
Lumiere建立於一個經過預訓練的文字轉圖像模型之上,首先會由基礎模型在像素空間生成圖像的基本草稿,接著透過一系列空間超解析度(SSR)模型,逐步提升這些圖像的解析度和細節。不過,採用空間超解析度技術針對影片的每一個時窗進行處理,可能會在不同時窗的邊界處,產生外觀上的不一致,這是因為每個時窗都是獨立處理,所以在時窗拼接時,可能會有細節上的差異。
研究人員採用了Multidiffusion方法來解決時窗上的不連續,藉由在不同的時窗上進行空間超解析度處理,並彙整處理過的片段,以確保影片片段在視覺上的一致性和連續性。
整體來說,Lumiere是一個強大的文字轉影片擴散模型,能夠生成高品質且動作連貫的影片,可用於多種影片編輯和內容創建任務上,諸如影片修復、圖像轉影片生成,或是生成特定風格影片等。
熱門新聞

2023-12-03

2024-04-24


2024-04-25

2024-04-26
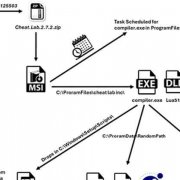
2024-04-22

2024-04-22
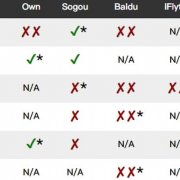
2024-04-25