2023台灣人工智慧年會
生成式AI今年非常火紅,各大軟體、硬體巨頭紛紛投入,就連處理器龍頭英特爾也喊出AI PC時代來臨,要讓生成式AI在內的AI應用成為未來PC的主流應用,甚至不只是PC,這樣的趨勢未來也有可能延伸到行動或邊緣裝置上。在聯發科負責電腦與AI部門的聯發科資深處長陸忠立在一場活動上也針對生成式AI在手機等行動裝置上的應用挑戰,提出他的觀察與解決之道。
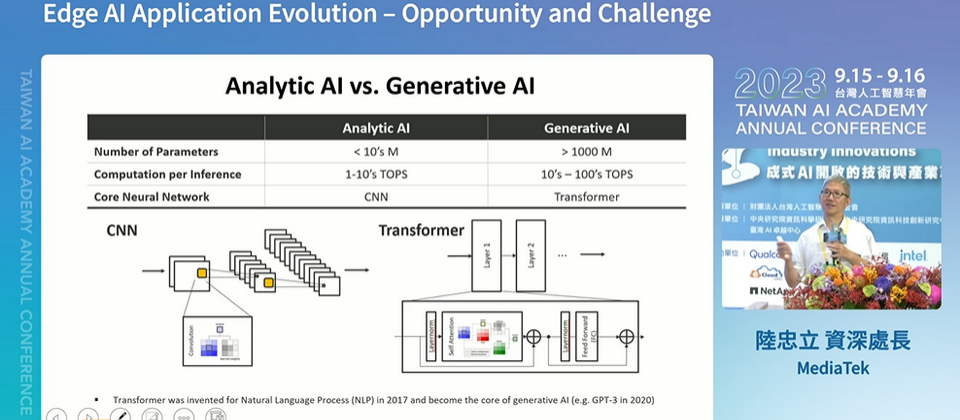
從應用角度來看,陸忠立表示,目前生成式AI應用主要分為4類,包括文生文、文生圖,以及圖生圖與圖生文。例如,ChatGPT就是一種文生文LLM模型的應用,而文生圖應用則有Stable Diffusion模型等。
他表示,傳統行動裝置上的AI應用,例如配備在行動裝置中的AI HDR影像增強、智慧降噪、影片畫質提升和影片幀數轉換功能,可以稱為分析式AI應用,這些應用背後使用的AI模型在核心神經網路架構上與目前的生成式AI應用有明顯的不同。
他用一個比喻來解釋,傳統分析式AI就像是一個擅長考試的學生,已經有一個標準答案存在,只需要盡量將你作答的答案接近這個標準答案就可以了,簡單來說,目標就是要考一百分。而生成式AI更像是一個具有創新思維的學生,「因為沒有標準答案可供參考,會給出多種不同的答案,可能回答1千次會得到1千種不同的結果。」他說,這也讓生成式AI在回答上更容易給出你可能沒想過的答案或創新點子。這正是生成式AI和分析式AI的差別。
可是,這使得生成式AI模型相較於傳統分析式AI模型,需要占用更多的頻寬、更多運算資源,例如生成式AI模型通常包含超過10億個參數,而分析式AI模型的參數僅是其百分之一,不到一千萬,也因此在處理模型推論時需要更高的AI算力,高於分析式AI的算力的10倍,大約需要10~100 TOPS的算力。
為何企業需要將生成式AI模型從雲端下放到Edge端執行?
陸忠立表示,主要有幾個原因,首先是隱私問題,有一些企業機敏資料或對話內容,可能不適合上傳到雲端,因此需要在Edge端來進行模型運算。此外,將模型部署到邊緣端可以使其輸出更貼近使用者身處的情境,還能夠在離線環境中使用,而且因為是在邊緣裝置上做運算,資料不需要傳輸雲端,反應能更即時。
但更重要的考量是成本。他表示,儘管模型訓練仍然在雲端中進行,但是將所有推論任務都在雲端執行成本相當高,如果邊緣運算設備具備有足夠的運算能力,那麼在本地處理這些任務可以幫助企業節省成本。
.png)
他強調,未來將是雲端和邊緣相互協作的模式。例如當用戶在終端裝置上輸入一段提問文字或上傳一張照片來進行生成時,首先由一個Arbitrator網路來決定是在本地端還是雲端來處理,對機敏性較高或者是低延遲的任務,將會在邊緣端的模型上處理。而對於需要更高精度輸出結果或需處理分布在全球大量資料的任務,就可以透過雲端模型執行。
他進一步補充,邊緣裝置目前能夠處理擁有約100億參數的AI模型推論的任務,(例如Llama 2 7B或Bloom 1B模型等),而雲端則可以處理多10倍,高達千億參數以上的模型推論(如GPT-4 或PaLM2模型)。
.png)
又以智慧型手機為例,陸忠立指出,智慧型手機運算能力受限,主要用於處理模型推論參數在10億到100億之間的AI任務,如相片處理或個人助理等。而PC的推論處理能力高於手機,但受限於記憶體頻寬,可以處理的參數量仍有限,大約在100億~300億之間,並以生產力相關的任務為主,例如使用Copilot協助撰寫信件、內容摘要或是簡報製作等。而如果模型參數超過700億,仍需要透過雲端進行處理,他坦言,目前在邊緣裝置上來執行這種規模的模型的挑戰難度非常高,
他表示,想要在邊緣裝置上執行LLM模型推論,必須考慮到記憶體配置(memory footprint)、運算能力和記憶體頻寬。這也是目前在邊緣裝置上執行LLM模型推論面臨的3大挑戰。
陸忠立也以執行一個70億參數的中型LLM模型對硬體的要求來舉例,執行這樣的模型推論需要智慧型手機的DRAM至少需具有7GB的記憶體,運算能力要達到40TOPS (相當於1秒內能處理512單字),記憶體頻寬則需要每秒傳輸70GB的速度。
可是,即便是今年上半最新款旗艦智慧手機,也很難達到這些要求,例如,單一LLM模型就需要占用7GB的記憶體空間,幾乎占掉了總體DRAM的一半。此外,儘管這款手機的算力達到40TOPS,看似可以執行LLM模型,但由於將所有運算資源都集中到LLM應用上,可能導致手機中其他App出現卡頓或是無法使用的情況。更大的挑戰是記憶體頻寬,最高傳輸速度只有50GB/s,不足以應付LLM需要每秒傳輸10個字的要求。
他強調,LLM模型對於記憶體頻寬要求很高,目前一般智慧手機的記憶體頻寬都不夠用,將是影響使用者體驗的重要關鍵。
目前每年AI模型複雜度正在以3到10倍速度增長,他認為,在一年可能只有2成硬體性能提升的前提下,很難趕上AI模型進展的速度。
為了解決這個問題,現今不少硬體廠商在設計處理器時,除了CPU、GPU外,開始新增了一個能針對AI工作負載加速的硬體,例如聯發科自己稱作APU處理器(AI Processing Unit)或是英特爾稱為DPU,專門處理包含生成式AI模型的推論任務等。
陸忠立表示,聯發科的APU處理器中,目前包含了兩個加速器,一個是DLA深度學習加速器,專門處理複雜的運算任務,另一個是BPU,類似DSP數位訊號處理單元,用來處理電腦視覺的相關任務,此外在BPU中還配備有本地記憶體,可直接在BPU中進行資料交換,減少對於DRAM的頻繁存取,也因此提高電力使用效率。
此外在硬體設計上,他們也針對Transformer模型進行優化,例如加強對於使用softmax函數的大型矩陣計算與LN(Layer Normalization)方法,進而改善其模型的吞吐量和算數的準確度。
.png)
除了採用新硬體架構,具備更高效能且更省電特性之外,陸忠立認為,更重要的是軟體,「如何透過軟體降低LLM模型執行所需的運算量和記憶體,這是在邊緣裝置中執行生成式AI應用的關鍵。」
他也分享聯發科的做法,從軟體架構來看,除了中間層的Middleware層,在這之上還有一個NeuroPilot軟體層,包括一套軟體工具和API,提供配接(adaptor)、編譯和runtime功能,用於聯發科平臺上開發高效的 AI 應用程式,上一層則可搭配PyTorch或TensorFlow等主流AI框架。此外,還提供了toolkit工具,使用戶可以更快速且容易在聯發科APU晶片系統上部署自己的模型進行相關測試及運用。
熱門新聞

2023-12-03

2024-04-24


2024-04-25

2024-04-26
2024-04-22

2024-04-22

2024-04-22