
Meta宣布開源可免費商用大型語言模型Llama 2,並找來微軟當作首批發表合作夥伴,展示雙方於人工智慧領域的擴大合作。用戶現在能夠方便地在Azure和Windows上部署Llama 2模型,而這有望使企業開發人工智慧應用的成本與障礙大幅降低。Meta和微軟在人工智慧領域的合作,從ONNX Runtime與PyTorch的整合開始,而現在進一步拓展至語言模型開源,展示雙方長期合作的決心。
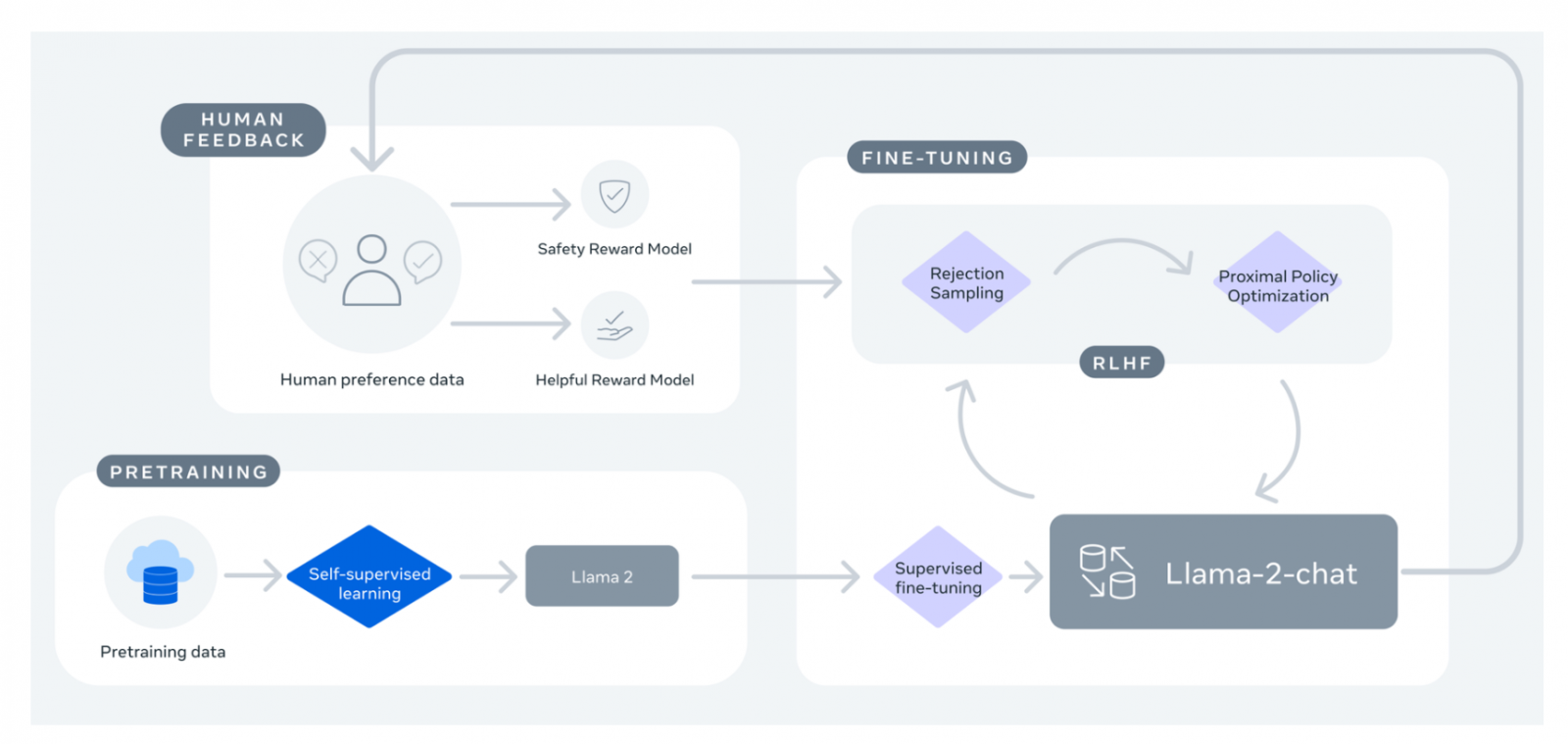
Meta在今年2月的時候發表LLaMA 1,而這個第一代LLaMA語言模型僅開放給人工智慧研究社群申請使用。LLaMA 1提供各種規模的版本,分別有70億、130億、330億及650億個參數等,這些基礎模型以大量未標註的資料訓練,用戶適合針對各種任務進行微調。
LLaMA 1一公開便受到研究人員的歡迎,Meta總共收到10萬個針對LLaMA 1的存取請求,而現在Meta開源Llama 2不限研究用途,更免費提供商業使用,開源的內容包括預訓練模型以及經調校模型的權重與起始訓練程式碼,Llama 2模型有70億、130億和700億參數三個版本。
Llama 2用於訓練的資料量,比LLaMA 1還多了40%,Llama 2預訓練模型總共使用2兆Token訓練,而且其上下文長度(Context Length)是LLaMA 1的兩倍。所謂的上下文長度,是指模型在生成文字時可以參考的文字長度,擁有更長的上下文長度,代表著模型能夠理解和生成更長的文字序列,有助於提升模型理解複雜文字結構和遠距的語義關係。Llama 2經調校的版本,則使用了超過100萬個由人類標註的資料訓練。
這次開源很值得注意的是經調校模型Llama 2-Chat,該模型運用人類回饋增強學習(Reinforcement Learning from Human Feedback,RLHF),針對對話應用最佳化,在廣泛可用性和安全基準上,Llama 2-Chat的表現已經比大多數開放模型還要好,而且根據人類的評估,其可用性已經和ChatGPT相當。Llama 2-Chat同樣也使用Llama 2授權,也就是說可用於學術和商業目的。
圖片來源 Hugging Face
當前用戶在商用大型語言模型的選擇並不多,即便不少企業或是學術單位釋出各種自己訓練的指令遵循模型,但多數模型可能無法商用,以Dolly 1.0模型來說,該指令遵循模型是Databricks以史丹佛大學的Alpaca模型,使用OpenAI API所產生的指令遵循資料集訓練而成,而OpenAI的使用條款,明確禁止用戶將其用於開發和OpenAI競爭的模型。
因此當一個語言模型的訓練資料來自另一個商用語言模型,那其商業用途便會受到限制,要開發一個可商用的語言模型,需要使用全新乾淨的指令遵循資料集,完全不能夠從ChatGPT或是網路等其他來源複製,否則便會污染資料集,也是因為這樣,當初Databricks才傾全公司5,000名員工之力,共同編寫指令遵循資料集,創建並開源可供商用與學術使用的Dolly 2.0。
而現在Meta開源可商用的Llama 2模型,以及可用性與ChatGPT相當的Llama 2-Chat模型,無疑是增加商用語言模型選擇,Llama 2-Chat也有望成為閉源聊天機器人的開放替代之一。
用戶現在可以在Azure AI模型目錄上選用Llama 2,並使用雲端原生工具設置內容過濾與安全功能,Llama 2也針對Windows本地端執行進行最佳化,但不只在微軟的Azure上,用戶也可以從AWS以及Hugging Face等其他平臺獲取Llama 2模型。
不過,雖然Meta稱Llama 2為開源模型,並可供研究與商業使用,但是Llama 2使用一個由Meta自創名為Llama 2的授權,從授權協議看起來Llama 2授權並非典型的開源授權,除了限制Llama 2的輸出不可用於改進其他大型語言模型之外,還附帶了特殊的商業用途條款,當公司的產品和服務超過7億活躍使用者,就必須向Meta申請授權,因此用戶在使用上仍需多加注意。
2023/7/21更正啟事:原文提及「超過7百萬活躍使用者,就必須向Meta申請授權」有誤,正確應為7億活躍使用者。內文已經更正。
熱門新聞

2024-05-06

2024-05-06

2024-05-06

2024-05-06

2024-05-07


2024-05-07