攝影/余至浩
近日,GPU大廠Nvidia股價大漲,再創新高,關鍵因素是ChatGPT帶來的生成式AI浪潮,使得大型企業與雲端資料中心對於生成式AI的運算需求不斷增長,進而帶動對新一波超級電腦的需求。
在30日Computex展覽舉行前一天,Nvidia執行長黃仁勳發表主題演講,他在長達近2小時的演講中不僅大談加速運算和生成式AI如何改變電腦產業,更展示用生成式AI技術來進行影音與歌曲創作的應用,此外,還推出了DGX GH200,這是一款採用Grace Hopper加速運算卡所打造的新一代生成式AI超級電腦,也是Nvidia首款Exaflop等級的DGX超級電腦產品。
值得一提的是,目前全球百大超級電腦排行榜上僅有橡樹嶺國家實驗室的Frontier,達到1.194 Eflop/s,突破exaflop效能的大關。不過,DGX GH200是一款商用超級電腦系統,預計今年稍晚上市,但價格尚未公布。
「 毫無疑問,我們正處於一個新的運算時代」黃仁勳在會中表示,這個新的運算時代有三大特色,其一是不只能夠理解文本和數位訊息,還可以理解多模態的訊息,並為每個行業帶來深遠影響;其次,大型語言模型的出現,使得電腦具備了理解使用者語言並執行相應指令的能力,從而降低程式撰寫的門檻。最後,這種電腦還能夠革新現有的應用,使得這些應用程式都因為AI的介入變得更優異。

他也透露,他們目前已與 1,600家生成式AI新創展開合作,將生成式AI技術應用於不同領域,包括語言處理、影音媒體生成、生物科學等。從早期採用者,到財富500強的企業,都已經開始利用生成式AI的自動化和共創能力來創造新的應用。他強調:「當今,生成式AI無疑是我們這個時代最重要的運算平臺。」
自2016年起,Nvidia每隔兩年推出一代新的AI超級電腦DGX產品,從最初採用Pascal架構的DGX-1和DGX-2,到後來使用Ampere架構的DGX A100 ,再到去年推出基於Hopper新架構的DGX H100,以及以H100所建構大規模運算叢集DGX SuperPod。
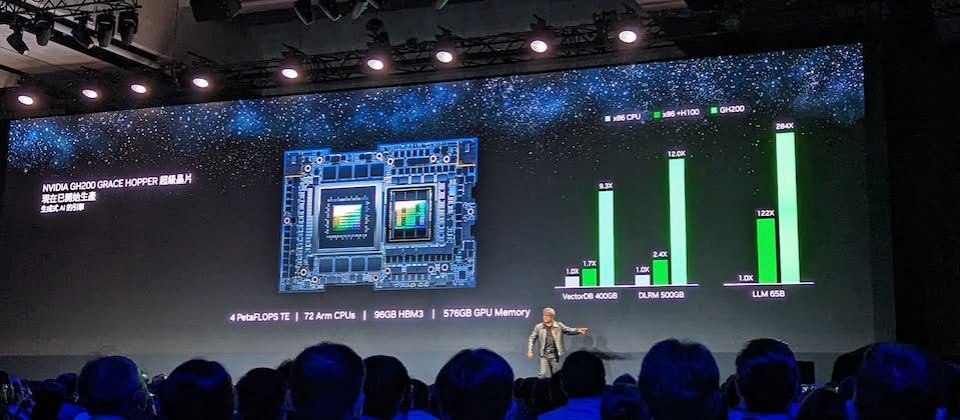
生成式AI技術的核心是大型語言模型(LLM),為了提升建立大型語言模型所需的運算處理能力,在會中,Nvidia發表了最新一代DGX GH200超級電腦系統,作為新一代生成式AI的加速運算引擎,該系統使用了256片Grace Hopper加速運算卡所打造。在每個Grace Hopper運算卡中,都同時採用基於Arm架構的Grace CPU與Hopper架構GPU的整合設計,來達到比現有第5代PCIe快7倍的資料傳輸和查詢速度。
每塊Grace Hopper加速運算卡擁有2,000億顆電晶體,可提供4 PetaFLOPS的運算效能,可有效支援ML模型訓練等高運算作業,以自然語言處理模型訓練為例,相較於使用x86架構CPU搭配Hopper GPU的伺服器,採用Grace Hopper的伺服器可以使NLP模型訓練速度提升4倍。

各Grace Hopper運算卡之間可以使用NVLink互連,每8個Grace Hopper相連形成一個pod運算叢集,最多可以支援256個Grace Hopper建立32個pods,以組成一個完整的DGX GH200系統,與當今全球超級電腦Top1的Frontier相比毫不遜色,可提供高達1 Exaflops的AI運算效能和144TB的GPU超大記憶體空間。
以32個pod運算叢集組成的DGX GH200系統,可提供高達1 Exaflops的AI運算效能
不僅如此,各Grace Hopper運算卡之間可以使用NVLink互連,每8個Grace Hopper相連形成一個pod運算叢集,最多可以支援256個Grace Hopper建立32個pods,以組成一個完整的DGX GH200系統,如此一來,在FP8精度下可提供高達1 Exaflops的AI運算效能。這樣的算力與近日公布全球超級電腦Top1的Frontier相比毫不遜色。
DGX GH200不僅提供Exaflops級的運算效能,還大幅擴充了記憶體容量。相比幾年前的DGX A100,DGX GH200的GPU記憶體容量增加了近500倍,甚至比DGX H100的640GB記憶體容量更高出許多,達到了驚人的144 TB的共享記憶體空間,對於需要大量記憶體的生成式AI等各種應用場景將會非常有用。
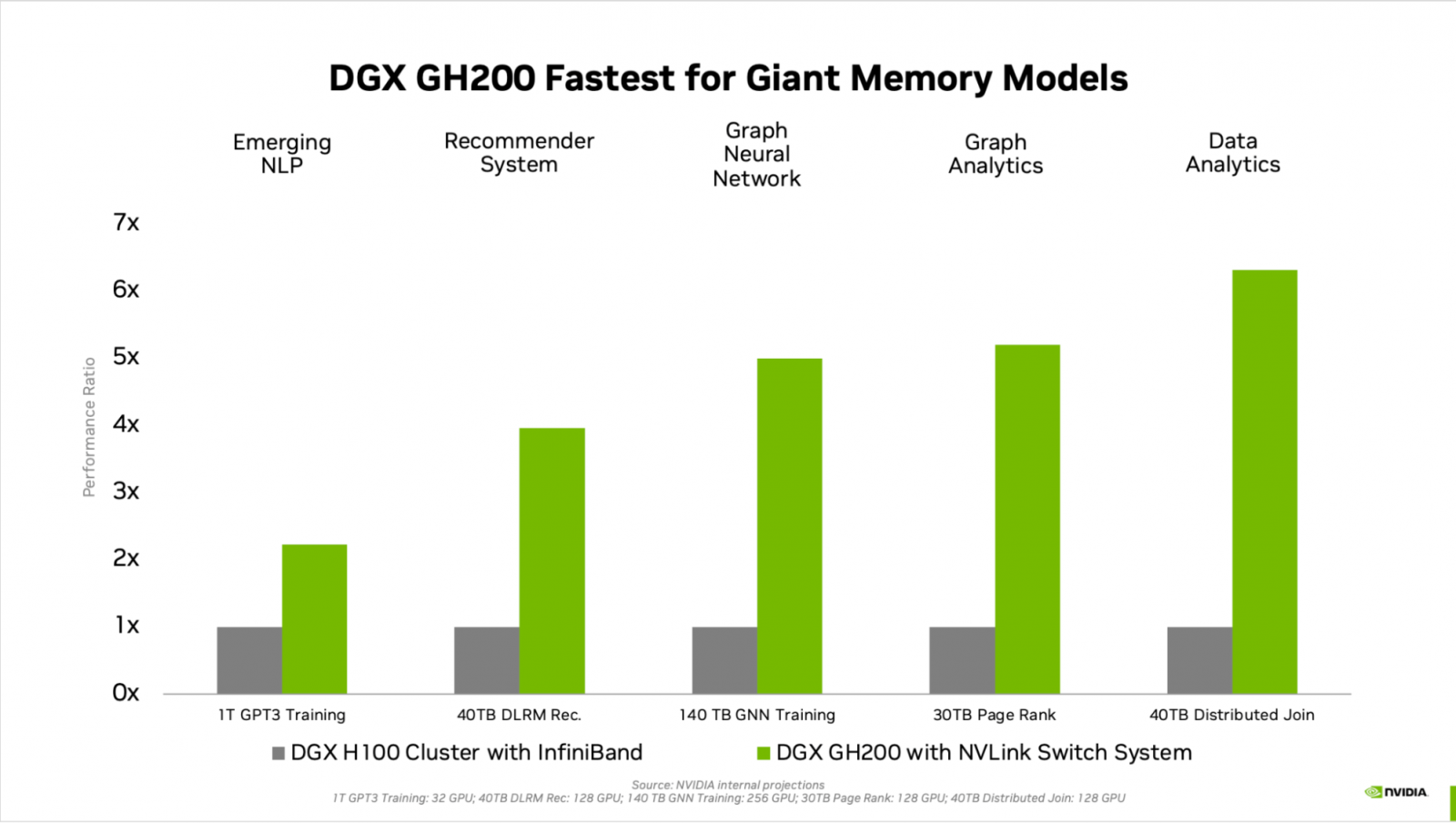
根據Nvidia的內部測試,在處理需要大量記憶體的AI工作負載方面,DGX GH200系統顯示出比DGX H100更好表現,不論是在GPT3模型訓練、深度學習推薦模型、圖形神經網路處理、繪圖分析方面,平均可獲得2~6倍不等的效能提升。圖片來源:Nvidia
根據內部測試,DGX GH200系統在處理需要大量記憶體的AI工作負載上表現優於DGX H100,平均可獲得2~6倍不等的效能提升,舉例來說,當使用1TB的記憶體容量進行GPT3模型訓練時,DGX GH200的處理速度比DGX H100快一倍,或是當以40TB記憶體處理深度學習推薦模型(DLRM)時,DGX GH200的速度則提升多達4倍,甚至在圖形神經網路處理方面速度更快上許多,足足有5倍之多。
目前已有少數大型雲端或科技業者決定採用DGX GH200,包括Google Cloud、Meta和微軟。
Nvidia目前並未公開DGX GH200的售價,但如果根據去年出貨的DGX H100作為參考,一臺搭載8組H100 GPU的8U高度GPU伺服器機櫃約為20萬美元(相當於臺幣6,100萬元),考慮到DGX GH200擁有最多256個Grace Hopper,其價格可能會高於這個範圍,但具體售價仍需待官方公布。
此外,黃仁勳也透露,未來考慮推出採用GH200系統的雲端服務,讓缺乏足夠資源與預算的企業,以後能更容易使用這項技術進行生成式AI應用開發與部署,以加快生成式AI和加速運算的發展。
同時,Nvidia宣布和SoftBank展開合作,將使用Grace Hopper在其5G網路中建構生成式AI 和軟體定義的5G堆疊架構方案。
除了推出針對生成式AI的專用硬體平臺,Nvidia還發表了可適用於資料中心網路的乙太網路平臺Spectrum X,結合了Spectrum-4 乙太網路交換器和BlueField-3 DPU資料處理器,以此提供更大規模頻寬和更低延遲。相較於傳統乙太網路,Nvidia強調,Spectrum X不論在效能或節能方面都足足提高了1.7倍,可用於加速生成式AI模型的開發與部署。

考慮到不同規模的企業對資料中心運算需求各有不同,Nvidia也推出加速伺服器的模組化參考架構Nvidia MGX,讓伺服器系統業者可以根據這個參考架構,來開發出不同配置的伺服器產品,以配合各種AI運算、HPC和模擬應用的需求。
雲達和Super Micro將會是首批採用的廠商,使用MGX 來打造下一代加速運算伺服器,永擎電子、華碩、技嘉與和碩後續將跟進採用,開發相應的產品。
在Omniverse數位分身產品方面,Nvidia也與廣告行業展開合作,將與全球最大廣告集團WPP合作,將生成式AI技術應用於數位廣告,開發支援廣告內容生成與結合Omniverse模擬分身技術,以提高廣告品質和使用體驗。
熱門新聞

2024-04-30

2024-05-01
2024-04-29
2024-04-29

2024-04-30

2024-04-30
2024-04-28

2024-04-29