
專業開發人員既要做好開發,也要做好溝通。『輸入若是垃圾,輸出也會是垃圾』對程式設計師同樣也適用,所以專業程式設計師會重視與團隊及業務部門的溝通,確保這種溝通的準確與流暢。
本章將介紹一些個人經歷:我會談到那些讓我第一次對使用C++感興趣的事物以及學習過程的心得體會。
問題
我想做的事情是,使程式設計師們能更簡單地把自己的工作發佈到不斷增加的機器中。解決方案必須是可移植的,還要使用一些作業系統提供的機制。當時還沒有C++,所以對於那些特定的機器而言,C基本上是唯一的選擇。我的第一個解決方案效果不錯,但實作之困難令人咋舌,主要是因為『要在程式中避免武斷的限制』。
機器的數量迅速增加,終於超過了負荷,也是到了必須對程式進行大幅修改的時候。但是程式已經夠複雜了,既要保證可靠性,又要保證正確性,如果讓我用C語言來擴展這個程式,我真擔心會搞不定。
於是我決定嘗試用C++來進行改進工程。結果是成功的:重寫之後的版本,比起老版本來說,在效率上有了極大的提高,同時可靠性也絲毫不打折扣。儘管C++程式天生不如相對應的C程式快,但是C++使我能在自己智力所及的範圍內,使用一些高超的技術,對我來說,用C來實作這些技術太困難了。
我被C++吸引住,很大的原因是因為資料抽象(data abstraction),而不是因為物件導向程式設計(OOP)。C++允許我定義資料結構的屬性,還允許我在使用這些資料結構時,把它們當作『黑盒子』來使用。這些特性若使用C來實現會困難許多。而且,其他的語言也不能把我所需的效率和可靠性結合起來,同時還允許我對付已存在的現有系統(和使用者)。
歷史背景
在1980年,當時我還是AT&T貝爾實驗室計算科學研究中心的一名成員。早期的區域網路雛型才剛剛以試驗性質在運行中,管理單位希望能夠鼓勵人們更常利用這種新技術。為了達到這個目的,我們打算增加5台機器,而這超出了我們現有機器數量的兩倍。此外,根據硬體行情的趨勢來看,我們最終將擁有多上許多的機器,我們就不得不面對因此引發的軟體系統維護問題。
維護問題肯定比你想像的還要困難許多。另外,類似於編譯器這樣的關鍵程式總在不斷變化中。這些程式需要仔細安裝;磁碟空間不夠或安裝時遇到硬體故障,都可能導致整台機器報廢。而且,我們不具備計算中心站的優越條件:所有的機器都由使用的人共同合作來負責維護。所以,我們需要一個整體的解決方案(global solution)來解決維護問題。
Mike Lesk多年前就意識到這個問題,並且用一個名叫uucp的程式,部分地解決這個問題,這個程式後來很有名氣。我說「部分地(partially)」,是因為Mike故意忽略了安全性問題。另外,uucp一次只允許傳遞一個檔案,而且發送者無法確定傳輸是否成功。
自動化軟體發佈
我決定扛著Mike的大旗繼續往下走。我採用uucp作為傳輸工具,透過撰寫一個名叫ASD(Automatic Software Distribution,自動化軟體發佈)的套裝軟體,來為程式設計師提供一個安全的方法,使他們能夠把自己的作品移植到其他的機器上,我預料這些機器的數量會很快地變得非常巨大。所以我決定採用兩種方式來增強uucp:更新完成後就通知發送者,並允許同時在不同的位置安裝一組檔案。
這些功能的理論都不很困難,但由於可靠性和通用性這兩個需求相互衝突,所以實現起來特別困難。我想要讓那些與系統管理無關的人使用ASD。為了達到這個目的,我應該恰當地滿足他們的需求,而且沒有任何瑣碎的限制。因此,我不想對檔案名稱的長度、檔案大小、一次運行所能傳遞的檔案數量等問題作任何限制。而且一旦ASD裡出現了bug,導致錯誤的軟體版本被發佈,那就是ASD的末日。
-
可靠性與通用性
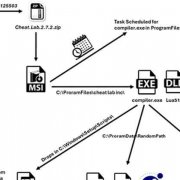
C沒有內建的可變長度陣列(variable-length array):在編譯時期修改陣列大小的唯一方式是動態地配置記憶體。因此,如果我想避免有任何限制,就必須使用大量的動態記憶體配置(dynamic memory alloction),並且無可避免地需要面對由此而產生的複雜性,但複雜性又讓我擔心可靠性。例如圖1(點此看圖)是ASD中的一個典型程式碼片段。
這段程式碼讀取檔案中用tf標示的一行的連續欄位。為了實現這一點,它反覆呼叫了幾次getfield,並把結果傳遞到不同的變換副程式(conversion routines)。
程式碼看上去簡單直觀,但是外表具有欺騙性:這個例子忽略了一個重要的細節。想知道嗎?那就想想getfield的回傳型態是什麼。由於getfield的值表示的是輸入行的一部分,所以顯然應該回傳一個字串。但是C沒有字串;最接近的做法是使用字元指標。指標必須指到某個地方;應該在什麼時候、用什麼方法回收記憶體?
C裡面有一些解決這類問題的方法,但都比較困難。一種辦法是讓getfield每次都回傳一個指標,這個指標指向呼叫它的新配置記憶體,而呼叫者則負責釋放記憶體。由於我們的程式先後4次呼叫了getfield,所以也需要先後4次在適當的場合呼叫free。我可不願意使用這種解決方法,寫這麼多的呼叫敘述真是很討厭,我肯定會漏掉一兩個。
所以,我再想了想,假如我能承受漏寫一兩個呼叫的後果,也就能承受漏寫所有呼叫的後果。所以另一種解決方案應該是完全無需回收記憶體,每次呼叫時,讓getfield配置記憶體,然後永遠不釋放。我也不能接受這種方法,因為它會導致記憶體的過量消耗,而實際上,透過仔細地設計完全可以避免記憶體不足的問題。
我選擇的方法是讓getfield所回傳的記憶體區塊的有效期限保持到下次呼叫getfield為止。這樣,總體而言,我就不用老是記著要回收getfield回傳的記憶體。方便行事的代價是,我必須記住,如果打算把getfield回傳的結果保留下來,那麼每次呼叫後就必須將結果複製一份(並且要記得回收用於存放複製值的那塊記憶體)。當然,對於上述的程式片斷來說,付出這個代價是值得的,事實上,對於整個ASD系統來說,也是合適的。但是跟完全無需回收記憶體的情況相比,使用這種策略顯然還是使撰寫程式的難度大增。結果,我為了使程式去除這種局限性所付出的努力,大部分都花在進行簿記工作(bookkeeping)的程式碼上,而不是花在解決實際問題的程式碼上。
-
為什麼用C
此時,你可能會問自己:「他為什麼要用C來做呢?」。畢竟我所描述的簿記工作用其他的程式語言來寫會容易得多,例如Smalltalk、Lisp或Snobol,它們都有垃圾收集機制和可擴展的資料結構。
我們很容易就排除了Smalltalk:因為它不能在我們的機器上運行!Lisp和Snobol也有相同的問題,但沒那麼嚴重:儘管我寫ASD的時候,那些機器能支援它們,但無法確保在之後的機器上也能使用。事實上,在我們的環境中,C是唯一確定可移植的語言。
退一步來說,即使有其他的程式語言可用,我也需要一個高效率的作業系統介面。ASD在檔案系統上做了許多工作,而這些工作必須既快速又穩定。人們會同時發送成千上百個檔案,可能有數百萬個位元組,他們當然希望系統能盡量快一點,而且一次就成功。
-
應付快速增長
我開始開發ASD時,我們的網路還只是個雛型(prototype):有時會失效,不能連接到每台機器上。所以我用uucp作為傳輸工具──我別無選擇。然而,在經過一段時間後,網路第一次變得穩定,並且成為了不可或缺的部分。隨著網路的改善,使用ASD的機器數量也在增加。到了大概25台機器時,uucp已經慢得無法輕鬆應付這樣的負載。是時候了,我們必須跨過uucp,開始直接使用網路。
對於透過網路進行軟體的發佈,我有一個好主意:我可以寫一個spooler來協調數台機器上的發佈工作。這個spooler需要一個在磁碟上的資料結構,來追蹤哪台機器成功地接收和安裝了套裝軟體,以便人們在操作失敗時,可以找到出錯的地方。這個機制必須十分強固(robust),可以在無人干預的情況下長時間運行。
然而,我遲疑了好一陣子,在ASD的最初版本中,那些曾經困擾過我的瑣碎細節,搞得我洩了氣。我知道我希望解決的問題,但是想不出來在滿足我的限制條件的前提下,應該如何用C來解決這些問題。一個能滿足限制條件的spooler具備下列特色:
●不但要有,還要盡可能有多一點的作業系統工具介面。
●避免沒有理由的限制。
●在速度表現上,必須比舊版本有本質上的提高。
●必須仍然極為可靠。
我可以解決以上的所有問題,除了最後一個。寫一個spooler本身就很難,寫一個可靠的spooler就更難。一個spooler必須能夠對付各種可能發生的奇怪失敗,而且還要始終讓系統保持著可以恢復的狀態。
我在除錯uucp的bug上花了幾年的功夫,然而我仍然認為,對於我的新spooler來說,要想成功,就必須立刻做到真正的bugfree。
進入C++
在那種情況下,我決定來試看看,是否能用C++來解決我的問題。
當時,我想C++有幾個特點對我會有幫助。
第一個就是抽象資料型態(abstract data type)的觀念。例如,我知道我需要把向每台電腦發送軟體的申請狀態儲存起來。我得想個辦法把這些狀態用一種可讀的檔案保存起來,然後在必要時取出來,在與機器對話時則應請求更新狀態,並能最終改變標示狀態的資訊。這一切都要求必須能夠靈活地進行記憶體的配置:我要儲存的機器狀態資訊中,有一部分是在機器上所執行的任何命令的輸出,而這輸出的長度是沒有限制的。
另一個優勢是Jonathan Shopiro最近寫的一個用於處理字串和串列(list)的套件(package)。這個套件使我能夠擁有真正的動態字串,而不必在簿記操作的細節上戰戰兢兢。該套件同時還支援了可容納使用者物件的可變長度串列。有了它,我一旦定義了一個抽象資料型態(例如命名為machine_status),就可以馬上利用Shopiro的套件定義另一個型態──由machine_status物件組成的串列。
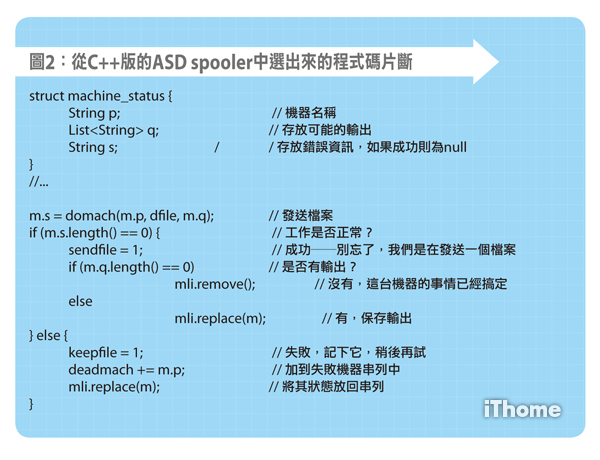
為了把設計說得更具體一點,圖2(點此看圖)列出了一些從C++版的ASD spooler中選出來的程式碼片斷。底下的變數m的型態是machine_status。
這個程式碼片斷對於我們傳送檔案的每台目的機器都執行一遍。結構體m將嘗試發送檔案的執行結果保存在自己的3個欄位(field)中:p是一個String,保存機器的名稱;q是一個String串列(List of Strings),保存執行時可能的輸出;s是一個String,嘗試成功時為null(空),失敗時則記載原因。
函數domach試圖將資料發送到另一台機器上。它會『返回』兩個值:一個是顯式的;另一個是隱式的──即透過修改第三個引數來達到返回的目的。我們呼叫domach之後,m.s反映了發送嘗試是否成功的資訊,而m.q則包含了可能的輸出。
接著,我們透過將m.s.length()與0比較來檢查m.s是否為空。如果m.s確實為空,那麼我們將sendfile設置為1,表示我們至少成功地把檔案發送到了一台機器上,然後我們來看看是否有什麼輸出。如果沒有,那麼我們可以把這台機器從需要處理的機器串列中刪除。如果有輸出,則將其狀態儲存在List中。變數mli就是一個指向該List內部元素的指標(mli代表machine list iterator,機器串列的反覆運算器)。
如果嘗試失敗,未能有效地與遠端機器對話,那麼我們就將keepfile設置為1,提醒我們必須保留該資料檔案,以便下次再試,然後將目前的狀態存到List中。
這個程式片斷中沒有什麼高深的東西。這裡的每一行程式碼都直接針對它試圖解決的問題。與相對應的C程式碼不同,這裡沒有什麼隱藏的簿記工作。這就是問題所在。所有的簿記工作都可以在程式庫裡被單獨考慮,只要做一次的除錯,然後就可以徹底不去管它。可以集中精力,在程式的其餘部分解決實際的問題。
這個解決方案是成功的,ASD每年要在50台機器上進行4000次軟體更新。典型的例子包含更新編譯器的版本,甚至是作業系統核心本身。相對於C,C++讓我得以從根本上,在程式裡更精確地表達我的意圖。
我們已經看到了一個C程式碼片斷的例子,它展示了一些隱秘的細枝末節。現在,我們來研究一下,為什麼C必須考慮這些細枝末節,再來看一看C++程式設計師要如何才可能避免它們。
-
C中隱藏的約定
儘管C有字元形式的字串常數(character string literal),但它實際上並沒有真正的字串概念。字串常數實際上是未命名的字元陣列的簡寫(由編譯器在尾部插入空字元來標識字串結尾),程式設計師負責決定如何處理這些字元。因此,舉例來說,儘管下面的語句是合法的:
char hello[] = "hello";
但是像下面這樣就不對了:
char hello[5];
hello = "hello";
因為C沒有複製陣列的內建方法。第一個例子中宣告了一個6個元素的字元陣列,元素的初值分別是'h'、'e'、'l'、'l'、'o'和'\0'(一個空字元null character)。第二個例子是不合法的,因為C沒有陣列設值運算子(array assignment),最接近的方法是:
char *hello;
hello = "hello";
這裡的變數hello是一個指標(pointer),而不是陣列(array):這個指標指向包含了字串常數"hello"的記憶體。
假設我們定義並初始化了兩個字元「串」(two character "strings"):
char hello[] = "hello";
char world[] = " world";
並且希望將它們連接起來。我們希望程式庫可以提供一個concatenate函數,讓我們可以寫成像下面這樣:
char helloworld[]; //錯誤
concatenate(helloworld, hello, world);
可惜的是,這樣並不奏效,因為我們不知道helloworld陣列應該佔用多大的記憶體。透過寫成像下面這樣:
char helloworld[12]; //危險
concatenate(helloworld, hello, world);
我們就可以將它們連接起來,但是我們連接字串時並不想去確實數一數字元的總數。所以,我們可能會透過下面的語句來分配絕對夠用的記憶體:
char helloworld[1000]; //浪費而且仍然危險
concatenate(helloworld, hello, world);
但到底要多少個字元才夠用?只要我們必須『預先指定字元陣列的大小為常數』,我們就要接受猜錯許多次的事實。
避免猜錯的唯一辦法就是動態決定串(注:本文之後的串都是在C裡討論的string,而非真實的C之字串character string)的大小。因此,例如我們希望可以像下面這樣寫:
char *helloworld;
helloworld = concatenate(hello, world); //有陷阱
讓concatenate函數負責判斷包含變數hello和world的連接所需要的記憶體大小、分配這樣大小的記憶體、形成連接及回傳一個指向該記憶體的指標等這些的工作。事實上,這就是我在ASD最初的C版本中所做的事情:我採用了一個約定,即所有串(strings)及類似串(stringlike)的值,其大小都是動態決定的,相對應的記憶體也是動態配置的。然而該在什麼時候釋放記憶體呢?
由於C的串程式庫無法得知程式設計師何時不再使用串了。因此,程式庫必須要讓程式設計師負責決定何時來釋放記憶體。一旦這樣做,我們就會有很多方法來用來在C中實作動態串。
對於ASD,我採用了3個約定。前兩個在C程式中是很普遍的,第三個則不是:
1.串是由一個指向它的首字元的指標來表示。
2.串的結尾用一個空字元來標識。
3.產生串的函數不遵循用於這些串的生命週期的約定。例如,有些函數回傳指向靜態緩衝區的指標,這些靜態緩衝區要保持到這些函數的下一次呼叫;而其他函數則回傳指向呼叫者要釋放的記憶體的指標。這些串的使用者需要考慮這些各不相同的生命週期,並在必要的時候使用free來釋放不再需要的串,還要注意不要釋放那些將在別的地方自動釋放的串。
類似"hello"的字串常數的生命週期是沒有限制的,因此,寫:
char *hello;
hello = "hello";
之後,不必釋放變數hello。前面的concatenate函數也會回傳一個『無限』存在的值,但是由於這個值保存在自動配置的記憶體區,所以使用完之後應該將它釋放。
最後,有些類似於getfield的函數將回傳一個生存週期經過精心定義但為『有限』的值。甚至不應該釋放getfield的值,但是如果想要將它回傳的值保存一段很長的時間,我就必須記得將它複製到時間稍長的儲存區中。
為什麼要處理3種不同的儲存生命週期?我無法選擇字串常數:它們的語義是C的一部分,我無法改變。但是我可以使所有其他的字串函數都返回一個指向剛配置的記憶體的指標。那麼就不必決定要不要釋放這樣的記憶體了:使用完之後就釋放記憶體通常都是對的。
不讓這些串函數在每次呼叫時配置新記憶體的主要原因是,這樣做會使我的程式十分巨大。例如,我將不得不像圖3(點此看圖)這樣重寫C程式碼片段(見前文<可靠性與通用性>的段落):
看來我還應該有一些其他的可選工具,來減少我所寫程式的大小。
使用C++修改ASD與用C來修改相比較,前者得到的程式更簡短,所依賴的常規更少。依此作為案例,讓我們回顧C++的ASD程式。該程式的第一句是m.s的設值敘述:
m.s = domach(m.p, dfile, m.q);
當然,m.s是結構體m的一個元素,m.s也可以是『更大的結構體的組成部分』之類的東西。所以,如果我必須自己記住要釋放m.s的位置,就必然需要對兩件事情有充分的心理準備。第一,我不會一次就正確獲得所有的位置;要清除所有的bug,肯定需要經過多次的嘗試。第二,每次明顯地改變某個東西的時候,肯定會產生新的bug。
我發現使用C++就不用再擔心以上這些細節。事實上,當我在寫C++的ASD時,沒有找到任何一個與記憶體配置有關的錯誤。
重複利用的軟體
儘管ASD的C版本裡有許多用來處理字串(character string)的函數,我卻從來沒想過要把它們封裝成通用的套件。向人們解釋使用這些函數要遵循哪些規則實在太麻煩了。而且,根據多年和電腦使用者打交道的經驗,我知道了一件事,那就是:在使用你的程式時,如果因為不遵守規則而導致工作失敗,大部分的人不會反躬自省,而是會怪罪到你頭上。C可以做好許多事情,但不能處理靈活多變的字串。
C++版本的ASD spooler也使用字元-字串函數(character-string function),已經有人寫過這些函數,所以我不用寫了。和我當初發佈的C字串規則比起來,編寫這些函數的人更願意讓其他人來使用這些C++字串副程式,因為他不需要使用者記住那些隱匿的規定。同樣地,我使用串程式庫作為副程式的基礎,來實作分析檔案名稱的特定模式比對工作,而這些副程式又可以被抽取出來用於別的工作。
此後我用C++設計程式時,還有過幾次類似的經歷。我考慮問題的本質是什麼,再定義一個類別來抓住這個本質,並確保這個類別能獨立地工作。然後在遇到符合這個本質的問題時就使用這個類別。令人驚訝的是,解決方案通常只在第一次編譯後就能工作了。
我的C++程式之所以可靠,是因為我在定義C++類別時,運用的idea比用C做任何事情時都多得多。只要類別的定義正確,我就只會按照我編寫它的初衷那樣去使用它。因此,我認為C++有助於直接表達我的思想並實現我的目的。
關於C++「為什麼沒有……」的問題
我在演講關於C++的議題時,最常聽到的問題之一是:「為什麼C++沒有(提問者最愛使用的程式設計環境的某種功能)?」
我的答案總結起來就是:「這種功能不是程式語言本身的一部分,所以你的系統中的C++是否具備這種功能,得看系統有沒有為它提供這樣的環境。」C++是一門程式語言,它本身並不是一種程式設計環境。如果你試圖在一個只實現最簡單的傳統環境的作業系統中執行C++程式,那當然不會很舒服。但是,這也給了C++兩個非常重要的特性:可攜性(portability)和可並存性(coexistence)。
一台機器如果支援C,那麼要支援C++就不難,也就是說,C++幾乎可以在任何地方運行。C++沒有對複雜作業系統的依賴性,例如不需要對垃圾收集機制或互動執行等功能的支援。
另外,由於C++可以使用存在於它所處的主機系統中的任何一種環境,所以它允許人們開發出能和正在運行的任何程式進行互動的程式。這種對環境極小的依賴性也使得C++程式可以在幾乎沒有支援環境的系統中運行。
C++能在任何已經存在的環境中運行。這使得人們可以在不重寫(甚至不用重新編譯)C程式的情況下,就能直接使用大量已有的C軟體,也使得人們能用C++寫出完整的作業系統。
(摘錄整理自本書第一、三章。摘文中引用的程式碼編排格式,請以原書為準)

我被C++吸引住,很大的原因是因為資料抽象(data abstraction),而不是因為物件導向程式設計(OOP)。C++允許我定義資料結構的屬性,還允許我在使用這些資料結構時,把它們當作『黑盒子』來使用。
C++沉思錄(Ruminations on C++)
Andrew Koenig, Barbara E. Moo/著;黃曉春/譯;
孟岩、陳錦輝/審校
博碩文化出版
售價:520元
Andrew Koenig
如果說C++的發明人Bjarne Stroustrup是C++領域的第一把交椅,那麼Andrew Koenig可以說是C++的第二號人物。他不但是Bjarne Stroustrup的好友,也是C++標準委員會的資深專案編輯,換句話說,您現在看到的C++標準,有許多都是經過他的手實作或審定出來的。難能可貴的是,他與Bjarne Stroustrup在C++方面的想法高度一致,這也是C++之所以能夠蓬勃發展的主因之一。
Barbara E. Moo
Barbara E. Moo是Andrew Koenig的老婆,除了與丈夫合寫了上述前三本經典著作外,還與Stanley B. Lippman合寫了著名的《C++ Primer》。在Stanley B. Lippman的《Inside the C++ Object Model》書中提到的Foundation專案,正是由Barbara E. Moo負責管理(除了其夫與Bjarne),算是C++當中的巾幗英雄。圖片來源/informit
熱門新聞

2024-04-22

2024-04-22

2024-04-22

2024-04-22

2024-04-22

{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}

2024-04-23